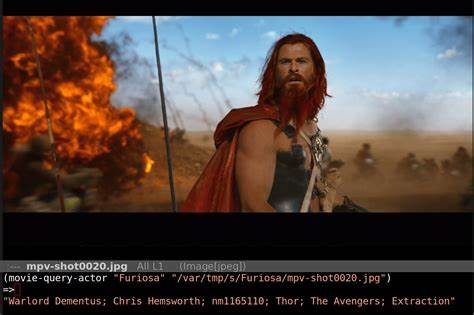
在当今数字化信息爆炸的时代,观影体验已经远远超出了单纯地欣赏电影的范畴。观众在观看影片时,常常会好奇屏幕上的那个演员到底是谁,这种好奇催生了对实时演员识别技术的需求。传统的查找方式通常依靠手动搜索或者片尾字幕,但效率低下且体验不佳。随着人工智能技术,尤其是基于大语言模型(LLM)的自然语言处理技术的飞跃,结合灵活的工具如Emacs编辑器,有可能为这个"屏幕上的演员是谁?"的问题提供全新的解决方案。 Emacs作为一款极具扩展性和高度自定义的文本编辑器,虽然最初被设计用于代码编辑和文本处理,但其丰富的插件生态使得它在数据调取和信息整合方面展现出强大能力。通过与LLM的结合,Emacs不仅能够作为一个强力的文本界面完成复杂的语言交互任务,还可以通过外部接口调用诸如谷歌的Gemini模型或OpenAI的GPT模型来进行实时演员识别和相关数据检索。
当前,大语言模型在图片和视频识别方面表现出令人惊叹的潜力,尤其是在通过文本描述与图像数据链接的多模态领域。当我们遇到电影片段中难以辨认的演员时,可以利用这些模型分析演员面部特征或声音信息,再结合庞大的影视数据库,如IMDb,返回最可能的演员信息。谷歌新的Gemini模型因其放弃"不要作恶"原则,更加毫无保留地进行人物识别,提供了更丰富和直接的数据支持。虽然这一特点引发了部分隐私和伦理方面的担忧,但从技术角度看,它极大提升了识别准确率和速度。 不过,实际操作中也暴露出一些挑战和技术难点。比如Gemini在匹配演员名字与IMDb ID时会出现偏差,部分时间只能正确匹配一半的信息,另一半变成随机错误。
这种数据不一致的问题,令全流程自动化识别依然存在不小难度。因此,结合人工复核或者其他数据校正机制成为可行的补救策略。而对Emacs用户而言,可以利用自定义脚本调用API、处理返回数据、生成覆盖画面(OSD overlay)等手段,打造一个便捷、交互性强的演员识别辅助工具。 在实际实现过程中,诸如图像格式转换、透明背景处理、数据请求响应时间以及错误调试,都需要开发者投入相当的时间和精力。尽管存在诸多技术难点,但成功实现后,观众将体验到极为便捷的观影辅助功能。比如,边看电影边自动弹出当前演员的详细资料,头像图片和知名作品一目了然,极大丰富观影过程的互动性和信息量。
从广义上讲,这种应用是人工智能技术赋能传统娱乐体验的一个缩影。未来不仅限于影视演员,也适用于音乐会现场、电视直播、体育赛事甚至社交媒体视频内容中人物身份的即时识别。随着技术完善和数据基础设施日趋健全,观众的观看习惯和信息获取模式将发生质变,更加注重即时获取对内容相关的上下文信息,而不是单纯被动接受影像。 此外,如何平衡技术效率与隐私保护也是探讨的重点。个人数据与图像的保护愈发受到关注,技术开发者和产业经营者需要在便利与伦理之间找到平衡点。可能的策略包括采用更严格的数据访问权限、引入匿名化处理技术、或允许用户自定义识别范围和数据显示程度,以维护观看体验的友好与尊重个人权利。
总的来看,结合Emacs与大语言模型的"谁是那个演员?"解决方案,开创了影视文化与人工智能融合的新方向。它不仅提升了用户对于影视内容的认知深度,也为技术创新在娱乐行业的应用提供了范例。通过不断优化算法性能、增强数据库的准确性与丰富性、提升系统的互动性,我们有理由相信未来的观影体验将更具智能化和个性化,让人们获得更为丰盈和愉悦的视听享受。 与此同时,技术爱好者和开发者们也能从这项应用中获取灵感和实践平台。利用开源编辑器Emacs的配置灵活性与大语言模型强大的理解能力,可以不断探索更智能的多模态数据处理方式,推动跨领域融合创新。与此同时,电影爱好者们能够以全新的视角感受影视作品的魅力,进一步激发对文化作品的探究与分享热情。
综上,屏幕上的演员身份识别虽是一个看似简单但隐含技术深度和应用广度的课题。通过Emacs和LLM的结合,已迈出了极具意义的一步。未来,随着算法的优化和应用场景的拓展,这种智能辅助方式必将成为每个影迷不可或缺的观影利器。拥抱这一趋势,我们将迎来更加智能、愉快而高效的影视文化新纪元。 。