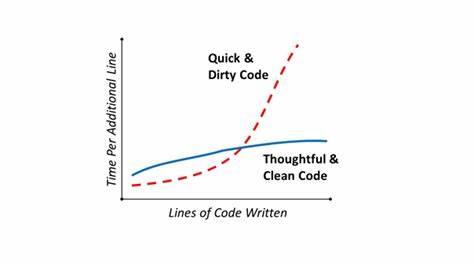
在当今数字化高速发展的时代,软件性能成为企业竞争力的重要指标之一。许多开发者和团队追求快速的代码实现,期望能够提升应用程序的响应速度和整体效率。然而,尽管快速代码似乎易于实现,但真正要科学且准确地衡量代码的执行效率,却常常令业界感到困惑和棘手。理解为何衡量快速代码如此复杂,对于开发者提升性能水平至关重要。 首先,快速代码的定义本身存在一定的模糊性。不同的应用场景和业务需求对“快速”的理解各异。
例如,某些场景可能关注代码的响应时间,强调实时反馈;而另一些则更关心吞吐量,即单位时间内处理的数据量。再加上硬件环境、网络状况及系统架构的多样性,使得对速度的衡量缺乏统一的标准。无需多言,准确评价代码性能的首要难点在于环境变量的复杂变化。 其次,代码的执行速度受诸多因素影响,单纯依赖通用的执行时间测量方法往往无法全面反映代码的性能表现。微观层面看,CPU处理器的缓存机制、分支预测、指令流水线以及内存访问延迟都会对最终速度产生关键作用。宏观环境则包括操作系统调度、并发竞争、网络延迟等不确定因素。
这些复杂交织的因素使得单次测量结果存在较大波动,难以精准捕捉代码的真实性能。 软件开发的复杂性进一步加大了衡量的难度。代码在实际应用中往往经过多层调用、模块组合和动态链接,每个组件性能可能千差万别。某段快速代码易于实现,但未必适用于所有调用路径或数据类型。性能瓶颈可能隐藏在下游模块或接口之中,单一代码段的测试结果难以代表整个系统的表现。如何设计合理的性能测试策略,覆盖真实应用场景,是衡量快速代码时必须面对的问题。
此外,现代软件系统越来越依赖于并发和分布式架构。多线程环境下共享资源的竞争与同步开销,网络请求的异步等待都可能导致测量误差。代码执行速度受到线程调度策略、锁机制、消息队列延迟等多重因素影响。所谓的“快速代码”,如果没有充分考虑并发带来的影响,测量结果极易偏离预期。开发人员需要采用专门的工具和方法,模拟多线程及分布式环境下真实负载,以提高评价的准确性。 还有一个不得不提的方面是性能测试本身的开销。
某些性能分析工具会对代码执行产生附加负载,导致测量数据扭曲。尤其在高频调用的关键路径中,过度的监控可能打破原有的运行状态,造成性能“悖论”。因此,选择合适的性能监控技术、合理的采样频率和测试条件是保证数据可信度的关键步骤。 除了技术因素,衡量快速代码还需要考虑开发团队的实际需求和资源限制。在项目初期,开发者追求快速迭代和功能实现,有时牺牲部分性能以换取交付速度。只有当系统规模扩大、用户数量激增,才会更加关注性能瓶颈和优化空间。
在此背景下,如何平衡开发效率与性能测量的投入,是每个团队必须权衡的现实课题。 针对以上挑战,业界提出了多种性能测量的最佳实践。例如,通过自动化测试框架集成性能测试,实时监控关键指标,能够较好地捕获代码性能的变化趋势。使用基准测试(benchmarking)方法,可在统一标准下对代码片段进行比较,减少环境差异带来的影响。此外,借助分布式追踪(distributed tracing)技术,开发者能更清晰地定位系统中各模块的性能瓶颈。 再者,代码优化不仅仅是单纯追求执行速度,更要关注内存使用效率、功耗以及系统稳定性。
现代应用程序常常运行于多样化设备和平台上,性能衡量指标需多维度综合考虑,比如响应时间、资源消耗、并发处理能力和可扩展性。只有建立科学全面的性能评价体系,才能真正实现快速代码的高质量应用。 总结来看,快速代码虽然看似简单易得,但其背后的性能测量充满复杂性和技术挑战。从环境变量的多样性,到硬件与软件层面的影响,再到并发与分布式架构的特殊需求,开发者必须采用科学严谨且灵活多样的工具和方法,持续监控和优化代码表现。只有深入理解衡量难点,才能在快速实现与高效性能之间找到最优平衡,推动软件系统达到卓越表现。未来,随着技术进步和测量手段的提升,快速代码的评估将更加精准和高效,为数字化时代的软件创新注入强大动能。
。