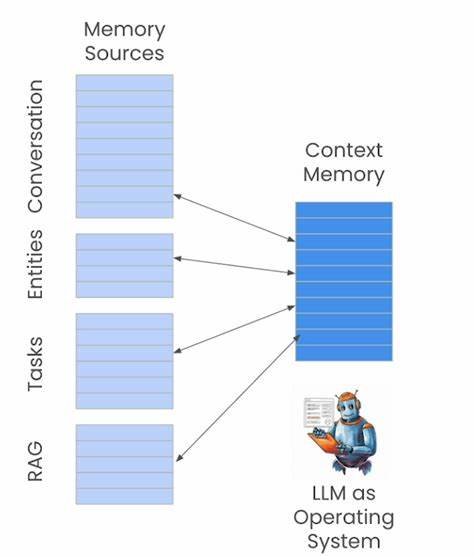
随着人工智能领域的迅猛发展,大型语言模型(LLMs)不仅在文本生成和理解方面展现出卓越的能力,更开始思考如何提升其“记忆”系统的有效性和智能化。外部记忆管理对于LLM而言,宛如人类的长期记忆,是积累经验、传承知识、实现智能进阶的关键环节。如何在存储容量有限的情况下,实现既不丢失重要信息又能保持高速检索的记忆方案,成为当前研究的焦点。人脑的记忆机制启发了我们对LLM外部记忆的新思考。人类并非将所有过往经历完整保留,而是通过战略性遗忘,让近期经历高度清晰,中期信息部分保留,远期记忆则逐渐模糊。借鉴这一机制,有助于设计出既能保留重要经验,又能避免信息冗余的记忆系统。
具体而言,可将每次互动(用户输入与模型响应)作为一对“键-值”对存储,其中键代表用户输入的嵌入向量,值则对应语言模型的响应内容。这些记忆单元类似链表结构,彼此关联,并拥有多重前瞻指针以保证访问路径的连续性。如此设计,在存储达到极限后,不是简单地整块清空旧数据,而是有选择地覆盖一部分旧记忆单元,同时保证链表结构的完整,避免记忆回溯被中断。通过这种“记忆衰退”机制,系统能够保留最新的完整记忆,对中期记忆进行部分保留,而较旧的记忆则逐步淡化,除非被标注为极其重要而优先保留。传统的向量数据库(如FAISS、Weaviate)通常对存储条目进行全有或全无的处理,删除操作一旦执行,语义关联即被完全切断,这与人类记忆的渐变式遗忘截然不同。采用链表般的部分记忆侵蚀策略,使系统模拟生物学中的“渐逝痕迹”模型,增强了记忆的灵活性和适应性。
这种差异性不仅提升了记忆的“温度感”,也为未来智能体在面对海量信息时如何精准管理记忆开启了新思路。关于存储成本的考量,假设经验的最大容量为每条128,000个token,配以768维的嵌入向量,每个token大约占4字节,嵌入向量采用float16类型占2字节,单条经验合计约513KB。若每天存储100条完整交互,则一年大约需要19GB内存,这在现代PC设备上并非难事。这一存储量可以通过自动总结、多轮对话压缩等方式进一步降低,例如利用大型语言模型对对话内容进行抽象提炼,或者借助文本压缩技术,达到4-10倍的压缩效果。为支撑链表结构的检索和存取,单纯的线性结构尚显不足,因此引入B树等索引机制,通过文件系统式的管理方式,优化存储组织并提升检索效率。此外,已有的实践经验表明,完全自研记忆管理系统难度大,采用现有向量数据库结合辅助的总结压缩策略更加实用。
将用户历史对话摘要压缩后分批导入数据库,再通过相似度搜索技术,智能选取相关记忆为下次对话提供支持,即贴近目前领先厂商如OpenAI、Anthropic的研发策略。在个性化助手场景中,记忆功能极其重要。诸如“请每天早上8点提醒我服药”这样的指令会转化为便于调用的事实型记忆。用户个人偏好、代码风格偏好、职业背景信息等,也能通过持续对话积累并自动归纳成为系统内可查询的知识点,极大提升交互个性化和智能化。检索效率方面,即便存储有10万条768维向量,所占空间约在300-450MB(float16),向量数据库检索延迟通常低于100毫秒,完全可以满足交互实时性的需求。为了确保存储库的新鲜度和准确性,还可引入基于访问频率的LRU淘汰机制、重要性权重以及时间戳过滤过滤策略。
未来升级空间表现为多样化标签元数据的支持、自动剔除低相关性记忆、用户友好的编辑界面(纠正错误或过期信息)、并利用辅助的语言模型周期性梳理“经验教训”,从而维护高质量的知识库。对于压缩存储的进一步深化,按需解码和动态压缩策略将减轻系统负担,实现更高效的数据管理和响应速度。不依赖脑型级高压缩或完美检索,而结合智能摘要、权重回收、分层存储的混合方案,即能达到理想中的80%记忆表现与实用性平衡,奠定了记忆增强型AI智能体的实用基础。总之,外部记忆在大型语言模型中的作用愈加重要,是通往具备持续学习力和长期适应性的智能生态关键。结合人类记忆的遗忘与强化机制,借助成熟的向量数据库与模型驱动的摘要压缩,有望为未来智能助理带来更自然、更灵活、更个性化的交互体验。真实模型将不再是瞬时记忆的机械体,而是会“懂得”遗忘、有“长远”视野的智能伙伴,真正实现从信息处理者向知识管理者的角色跃迁。
。