人工通用智能(AGI)代表着人工智能发展的最高理想,即开发出能够在多数领域具备与人类相当甚至超越人类水平的智能系统。相比于现阶段专注于单一任务的人工智能,AGI不仅能处理复杂多样的任务,还拥有学习新技能和自主推理的能力。然而,衡量和追踪AGI的发展进度却面临巨大挑战。 首先,AGI的定义本身存在分歧。不同的学者和研究机构对AGI的理解差异较大,有的人强调性能表现,即机器能在大多数人类任务中达到或超越人类水平;有的则关注机器的内部机制和学习能力;另一些人则从经济影响或者伦理社会层面进行考量。这种多元化的定义使得设计统一且有效的基准测试变得复杂。
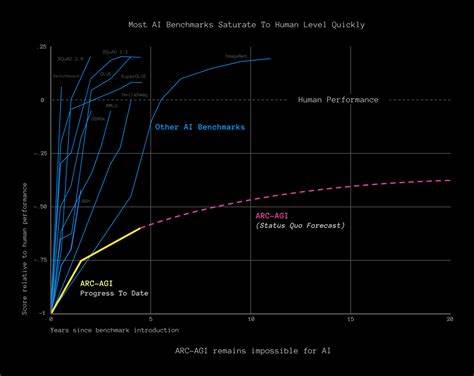
传统的人工智能评测往往依赖于特定领域的任务,如图像识别、语言理解或游戏竞技,但这些测试难以全面反映AGI应具备的广泛适应能力和灵活推理能力。以往经典的"图灵测试"曾被视为AGI的衡量标准,即人工智能系统是否能够在文本交流中骗过人类判定。但随着大规模语言模型如GPT系列的出现,图灵测试的效用逐渐减弱,因为这些模型尽管表现优异,却常常在简单逻辑或者常识判断上出现明显错误,暴露了它们固有的局限性。 为此,研究者们提出了更具挑战性的评测工具。例如,阿布斯特拉克ション与推理语料库(Abstraction and Reasoning Corpus,简称ARC)由谷歌前工程师弗朗索瓦·肖莱尔发起,旨在考察机器的流体智能 - - 即在有限示例基础上快速抽象概念与推理的能力。ARC中的任务涉及几何图形的模式识别和规则推断,这对人类来说较为轻松,但对于目前的人工智能系统却极具挑战性。
最新版本ARC-AGI-2更增加了任务复杂度,要求模型在有限算力和时间内解决环境中多步骤、多规则的视觉推理问题。尽管一些顶尖模型取得了突破,但与人类平均水平仍存在显著差距。 除此之外,跨模态评测工具如General-Bench正在尝试将文本、图像、视频、音频与3D环境结合,通过多样化的任务展现AI系统应具备的综合能力。这类测试不仅要求识别和生成信息,更着重体现机器在不同信息通道间的联动和创造力,以及处理伦理判断等复杂认知过程的能力。面对如此复杂多样的评价需求,现有模型尚未能实现全方位的胜任。 虚拟环境的应用也为AGI测试提供了新思路。
Google DeepMind开发的Dreamer算法已可处理超过一百五十种任务,涵盖视频游戏操控、虚拟机器人控制和沙盒游戏如Minecraft中的资源获取与规划。这类环境能够一定程度上模拟现实世界中的感知、探索和长期规划等能力。然而,这些模拟缺乏现实物理世界的不可预测性和细腻的人际互动,限制了其在AGI评测中的真实性和全面性。 针对社会情境的理解及价值体系的评估,近年来亦成为AGI基准测试的重要方向。复合任务和动态交互的设计使得AI不仅需具备单纯的认知能力,更要处理复杂的道德困境、人类情绪和社会规则。例如,"Tong测试"设想赋予虚拟代理自主探索和设定目标的权利,同时检验其对突发社会事件和伦理选择的反应。
此类评测追求对人工智能的人文关怀和社会适应力进行深入考察,为未来的AGI研发提供更为全面的指标体系。 物理操作能力是否是AGI必要条件亦存在争议。部分观点认为,智能更多体现于软件层面的自主学习及推理能力,物理执行可视为附加功能。比如,有些机器人尚欠缺处理复杂物体和环境细节的技能,如旧房屋的管道维修被认为是需要至少十年才能突破的难题。相对而言,纯软件系统已经可以在很大程度上展示人类智能的某些方面。 此外,人类智能与机器智能的本质差异使得简单地用类似智商测试的量化指标来衡量AGI并不现实。
人类智商测试往往聚焦于记忆、推理、数学和语言能力,而智能的社会性、创造性和环境适应性却难以量化。机器往往在某些任务中迅速提升,但在跨情境迁移和常识推断方面显著落后。有学者提出,观察人工智能在真实世界中的表现,如其在科学发现、自动化岗位替代等领域的实际应用,可能是评判AGI能力的重要标准。 尽管评测体系尚不完善,人工智能在若干领域的突破已引发广泛讨论,如GPT-4.5在短时间内能够获得人类判断者73%的识别错误率,显示了其逼近人类交流水平的潜力,但同时也暴露了其在细节处理和逻辑稳定性上的不足。此现象体现了人工智能"似是而非"的特点 - - 表现出强大技能,却依赖于统计模式而非真正理解。 展望未来,AGI基准测试将趋向于更加多维和动态,结合视觉、听觉、语言和触觉等多感官输入,融入环境交互、社会伦理与目标设定等复杂维度。
为避免"克莱弗·汉斯效应",即看似智能实则依靠捷径的误判,测试设计需要严密防止AI利用漏洞和外部提示。更重要的是,基准测试应促进理解AI内部机制与潜在推理路径,避免盲目依赖表面表现。 业界、学界正在积极推动国际合作,打造公开、透明且动态更新的AGI测试平台和竞赛激励机制。ARC Prize Foundation即通过巨额奖金鼓励开发更强泛化能力的模型,同时限制计算资源以倡导高效创新。类似的开放竞赛有助于形成行业标准,推动人才和技术积累。 总结来看,AGI的概念仍在持续演进中,界定标准复杂且富有争议。
基准测试虽然不能穷尽智能的全部方面,但通过不断挑战AI系统的新能力,提供了比较客观的进步坐标。未来对AGI的评估,将不仅是算法与算力的较量,更是对人工智能如何理解、适应并负责参与人类社会的综合考验。只有建立起科学严谨、多层次且灵活的评测体系,才能确保AGI技术的发展既充满活力又稳妥可控,推动其最终实现助力人类进步与繁荣的理想。 。