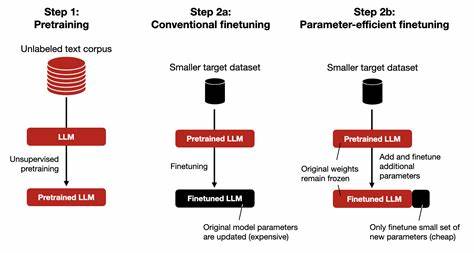
随着人工智能技术的不断发展,大型语言模型(Large Language Models,简称LLM)在自然语言处理领域展现出强大能力。训练和微调这些模型通常需要庞大的计算资源和丰富的数据支持,同时保障训练过程的透明性与可信度也变得日益重要。在这一背景下,去中心化协议作为一种新兴的技术手段,为可验证的LLM训练与微调提供了有效的解决方案。去中心化协议通过分布式账本技术,实现训练过程的全流程记录与追踪,使得参与者可以验证模型训练的合法性及准确性,避免中心化系统中存在的信任瓶颈和单点故障风险。传统的LLM训练多依赖云服务商或单一机构,存在数据隐私泄露、模型偏见无法追踪以及训练过程缺乏透明的问题。去中心化协议运用区块链技术将训练任务和数据分散在多个节点上,通过智能合约自动执行训练指令与结果验证,确保各方的信息同步且不可篡改,从而在保护数据隐私的同时提高整体系统的安全性和可靠性。
在微调环节,去中心化方法同样展现出巨大优势。细粒度的微调通常需要针对特定领域或任务进行定制化优化,以提升模型的针对性和准确度。通过去中心化网络,多个参与者能够协同上传微调数据,提交优化参数,并且通过共识机制来验证微调结果的有效性,杜绝恶意篡改和欺诈行为,保证最终模型质量。此外,采用去中心化协议能够显著降低训练和微调的成本。传统由中心服务器进行的大规模计算往往费用高昂且资源有限,而在分布式环境中,全球各地的计算资源得以充分利用,形成一个开放、共享的训练生态系统。这样不仅增强了模型开发的灵活性,也促进了社区参与和创新,激发了更多研究人员和开发者的积极性。
去中心化协议还可以结合零知识证明等密码学技术,进一步提高训练过程的隐私保护和安全水平。训练数据敏感性强,企业或组织往往对数据共享持谨慎态度。零知识证明的引入使得参与者可以在不透露原始数据的情况下验证计算的正确性,极大地缓解了隐私顾虑和合规风险。同时,这些技术能够保障模型参数的机密性,对防止模型窃取和逆向工程提供有力支持。当前,去中心化可验证LLM训练协议逐渐吸引了众多人工智能企业、科研机构以及开源社区的关注。随着相关白皮书和技术文档的发布,业内对其实施方案、共识机制设计、安全保障措施等方面进行了深入探讨。
未来,随着去中心化技术的成熟与完善,基于这些协议的模型训练平台有望成为主流,推动人工智能研发进入一个更加开放、透明和可信的新阶段。从应用角度来看,去中心化协议在医疗、金融、法律等对数据安全和合规性要求极高的行业,展现出独特优势。通过可验证的训练过程,不仅提升了模型的可信度和适用性,也为监管机构提供了透明的审计依据,促进人工智能技术规范健康发展。此外,去中心化模型训练体系通过开放生态系统,促进了多方数据资源整合和共享创新,有利于打破数据孤岛,实现跨域知识融合,推动人工智能技术更快落地和普及。展望未来,去中心化可验证LLM训练协议将融合更多前沿技术,如联邦学习、多方安全计算等,形成更完善的生态体系。在算法优化、大规模数据管理、模型评估及反馈等环节实现更高效、安全的协同,破解当前人工智能模型发展的瓶颈,为行业发展注入强劲动力。
总之,去中心化协议为大型语言模型的训练与微调带来了革命性的变革。它不仅解决了传统集中式训练的诸多痛点,提升了透明性、安全性和信任度,更促进了资源共享和开放创新。随着技术的进一步成熟和标准化推进,去中心化可验证训练体系必将成为人工智能研发的重要基石,助力人工智能迈向更智能、更安全、更高效的未来。