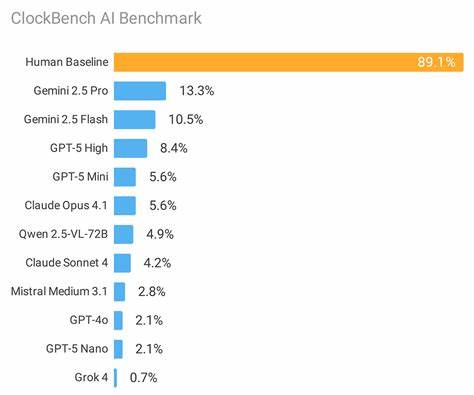
随着人工智能技术的飞速进步,视觉推理成为衡量模型智能水平的重要指标之一。尽管现有大型语言模型(LLM)在语言处理和逻辑推理任务中表现优异,但对于直观的视觉现实场景,尤其是模拟时钟读取这一简单任务,模型的表现却意外地低于人类水准。ClockBench作为一项创新性的视觉推理基准,专门设计用于评估模型解析模拟时钟的能力,揭示了目前AI视觉理解和时间推理领域的瓶颈。 ClockBench基准测试包含36个不同的时钟面,共计180个时钟图像,以及720道相关问题,覆盖了从读取时间、加减时间、旋转指针到跨时区转换等多种场景。人类测试者在该任务中的准确率高达90.7%,表现几近完美,显示出人类在视觉感知与时间认知上的天然优势。相比之下,当前领先的人工智能模型最高准确率仅为39.4%,而多数顶尖模型的表现更低,甚至不足20%,这反映出模型在将视觉信息与复杂时间推理结合时存在明显短板。
这项测试背后的核心挑战在于视觉推理和时间理解的深度融合。模拟时钟读取涉及对指针位置的精准识别、角度的理解以及时间单位之间的转换,这对于人类而言极为直观,但对机器来说则需要在视觉识别的基础上进行复杂的空间推理和时间计算。传统的LLM主要优化在文本理解和生成,缺乏足够的视觉感知训练,导致其难以胜任此类任务。尽管多模态模型试图将视觉与语言结合,但仍未能达到理想的解析效果。 ClockBench数据集还特别设置了旋转指针和跨时区转换的复杂问题,进一步考验模型在动态视觉调整和跨域时区换算的综合推理能力。当前AI模型在这些任务上的劣势凸显,反映出它们对时间和空间环境变化的适应能力有限。
这不仅对ClockBench测试有启示意义,更在更广泛的视觉推理和应用场景中暴露了挑战。 这项基准的推出,引发了AI社区对于视觉推理瓶颈的广泛关注。研究人员建议,未来的突破可能需要采用全新思路,结合更强的视觉感知模块以及面向时钟读取等具体应用任务的训练策略,或者通过增强多模态信息融合技术,实现对视觉时间信息的深层理解。此外,模型架构的创新和更丰富的训练数据集同样是提升性能的关键因素。 ClockBench公开了部分数据集及评估代码,鼓励开发者和研究者参与实验与改进,为攻克视觉时间推理难题提供了良好平台。该基准的成功不仅为模型能力提供了新的评估维度,也开启了大模型在视觉理解领域迈向更高水平的新篇章。
总结来看,ClockBench基准测试清晰展现了人类和顶级AI模型在视觉时间推理领域的显著差距。尽管AI模型在文本和逻辑推理表现日益强大,但其在模拟时钟识别与时间推算上的低准确率提醒我们,现有技术尚未完全掌握视觉与时间信息的深度整合。未来,随着研究不断深入及技术创新,AI视觉推理能力有望取得飞跃,为实现更智能、更具人类直观理解的人工智能奠定坚实基础。 。