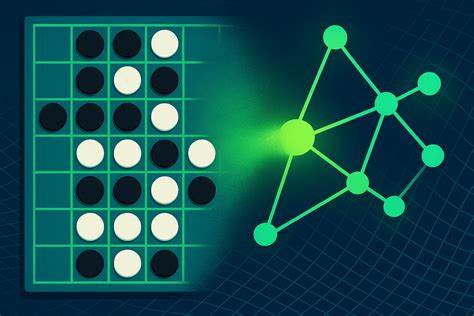
随着人工智能技术的迅猛发展,关于大型语言模型能否真正理解和构建世界知识的讨论愈发热烈。近期,哥本哈根大学的研究团队通过对经典棋类游戏Othello(黑白棋)的深入实验,为“世界模型假说”提供了新的有力支持,进一步挑战了外界对大型语言模型认知能力的传统认知。实验通过训练多款最先进的大型语言模型,仅依据棋步序列数据,让模型自行学习游戏规则和棋盘结构,成功验证了这些模型确实能够形成对游戏空间结构的内部表征。这一发现对于深度学习领域意义深远,也为未来人工智能系统的设计提供了重要思路。 Othello是一款经典的策略棋盘游戏,其复杂的棋盘空间结构和精准的操作规范,使其成为研究空间认知和规则学习的理想对象。传统观点认为,语言模型仅通过语料库中的文本串联关系难以把握视觉空间信息及其复杂抽象的规则体系,很难像人类一样真正“理解”游戏环境。
然而,哥本哈根团队的最新研究挑战了这种看法。他们将七种不同架构的语言模型,包含GPT-2、T5、Bart、Flan-T5、Mistral、LLaMA-2以及Qwen2.5,分别训练来预测Othello棋局中的下一步移动,仅利用两套数据集:一套由约14万局实际比赛组成,另一套由数百万局合成游戏数据组成。 与早期相关实验最显著的不同在于,团队引入了全新的“表示对齐工具”,借此能够比较这些模型在内部形成的棋盘空间表示的相似性。这项工具突破了早期研究比如OthelloGPT所面临的分析局限,能够更精细地揭示模型内部如何捕捉棋盘的空间结构。研究结果显示,模型不仅能准确地预测下一步棋子落点,更重要的是,不同架构的模型所学习到的空间地图高度契合,表明它们形成了类似人类直观理解棋盘的内部认知结构。 在性能表现方面,训练所用数据的规模和模型架构同样起到关键作用。
在真实游戏数据集上,大多数模型训练全量数据后,其错误率低于6%,表现卓越。而在合成数据集上,错误率随着数据规模的增大呈现显著下降,从最初2000局时的约50%迅速降至完整数据集时的不足0.1%。这凸显了数据量对模型学习空间认知能力的显著影响。 值得注意的是,具备预训练语言能力的模型如Flan-T5和LLaMA-2,并非在Othello游戏表现上总是优于那些从零开始训练、没有语言预训练背景的模型。此现象暗示,构建Othello棋盘的世界模型能力,并不依赖于对自然语言的先验知识,而主要依赖于对棋步序列这种单一模态数据的学习和抽象。此发现大大加深了我们对于大型语言模型在象征符号与现实世界对应关系——即符号扎根问题——上的理解。
此次研究不仅挑战了部分批评者关于单模态系统难以掌握视觉空间信息的观点,也证明了语言模型在没有接受任何视觉输入的情况下,能够抽象出高度结构化的空间和规则知识。在符号扎根问题上,模型成功将象征符号如“C3”这类抽象标记,与棋盘上的具体位置及其周边空间关系对应起来,超越了简单的符号排列组合,将其赋予了实际含义与空间语境。 哥本哈根大学的研究员Yifei Yuan与Anders Søgaard强调,这项研究通过借助表示对齐工具和大规模实验设计,显著提升了对“Othello世界模型假说”的证据强度,远超以往相关实验成果。该工作为AI研究领域打开了新的探索方向,即利用语言模型在序列数据中发掘结构与规则,从而实现对复杂环境的内在感知和理解。 人工智能领域一直在思考机器是否真正“理解”所处理的信息,还是仅仅停留在统计学模式识别和模仿层面。此次实验无疑为“理解”赋予了新的定义和维度。
大型语言模型具备了从单一模态模拟数据中学习复杂抽象规则和空间结构的能力,这表明它们不仅仅是在执行统计上的概率计算,更似乎构建了某种形式的“心理表征”或内部世界模型。 这样的能力对未来AI应用将产生深远影响。在机器人导航、游戏AI、智能助手乃至认知计算等领域,模型能否建立并利用世界模型直接关系到智能表现的质与量。特别是在符号扎根和多模态融合方面,该研究提出的思路和工具将助力更高效的模型训练和解释。同时,这也对AI哲学和认知科学提出新课题,即机器内部的“思维”与“理解”到底何以定义以及如何测量。 这场关于Othello游戏的实验,虽然具体,但揭示了大型语言模型潜在的认知深度和广度,表明其远超表层的模式拟合,具备某种形式的推理与规则内化能力。
未来,研究团队还计划拓展类似方法至其他游戏与任务,验证语言模型在不同领域和复杂环境中的世界模型构建能力,推动AI向真正智能迈进。 总体来看,哥本哈根大学此次重塑大型语言模型世界模型假说的研究,不仅刷新了学术界对语言模型认知边界的认知,也为AI技术发展指明了新的方向。它打破了传统观念中的桎梏,让人们看到语言模型凭借简单的序列数据同样可以洞悉结构复杂且高度抽象的空间规则。这不仅为未来更多领域的AI应用提供理论基础,也为AI思考自身“理解”与“意识”问题提供了新的视角和启示。AI正在逐步跨越表层统计,迈向真正的认知智能时代。