随着大规模语言模型(LLM)逐步走向普及,如何在有限资源下高效训练成为工程实践中的核心问题。量化训练结合纯 CUDA/C++ 实现,能够在不依赖高级框架的前提下直接控制内存、通信与算子执行,发挥显卡真正的计算与带宽潜力。本文围绕量化 LLM 训练在纯 CUDA/C++ 环境下的设计理念、实现要点与优化实践展开,帮助读者理解如何在单机多 GPU 环境中实现高吞吐、低显存占用且可复现的训练流程。文中内容基于实际项目经验,兼顾可操作性与理论依据,便于工程化落地。 为什么在纯 CUDA/C++ 中实现量化训练值得关注?量化训练通过降低表示与计算精度,显著减少内存占用与通信带宽,从而允许在相同硬件上训练更大的模型或使用更大的 batch。与基于 Python 的训练框架相比,纯 CUDA/C++ 实现可以在内核级别进行更细粒度的性能优化,避免 Python 层的开销与不必要的同步。
更重要的是,在纯 C++ 中可以灵活实现自定义的内存分配器、零拷贝通信和专门针对 PCIe 或 NVLink 拓扑的全聚合算法,从而在多 GPU 环境中获得更高的带宽利用率。对于希望在单机多卡上以最小代价完成模型训练的团队,纯 CUDA/C++ 提供了更高的可控性和潜在性能提升空间。 关键设计要点包括低精度算子支持、内存与优化器状态分片、激活重计算策略、主机端与设备端的权重/动量 offload,以及高效的多卡通信。低精度算子方面,应支持常见的数据类型如 bf16 与 fp32,同时还要引入更低精度的矩阵乘法格式如 fp8 或芯片厂商提供的 e4m3 等。训练主权重通常使用较高精度的 master weight,而用于前向/反向的矩阵乘法可选择低精度以换取更高的吞吐。实现上需要在 kernel 层提供对多种 dtype 的分发机制,确保在不同组合下都能正确提取 Tensor 指针并调度对应的 CUDA kernel。
把内核实现为只接受基础类型参数,再在上层封装 Tensor 接口以便抽象与复用,有利于代码可维护性与性能。 内存管理在量化训练中至关重要。合理的分配器设计需要同时监控并管理权重、激活、优化器状态、梯度和主权重(master weights)的占用。为了解决显存不足问题,可以采用梯度累积与激活重计算(recomputation)策略。重计算可以选择性地对不同组件进行启用,例如仅对轻量级的归一化与激活函数(如 SwiGLU、RMSNorm)重计算以节省大量激活内存,而对矩阵乘法进行重计算则会带来明显的额外计算开销,但在显存瓶颈严峻时仍是有效手段。实现上应支持模块化的重计算策略,允许按层或按块启用不同的重计算选项,以便在速度与内存之间做出适当权衡。
优化器和 ZeRO 分片是多卡训练高效扩展的基础。通过 ZeRO 的多个级别可以分别对优化器状态、梯度和权重进行分片,从而线性降低单卡内存压力。实现时需设计灵活的分片策略,允许独立控制权重分片与梯度分片的开关,因为在低精度训练下,权重分片往往优先带来通信与内存带宽的收益,而梯度分片会增加同步复杂度。为了兼顾训练速度与内存占用,常见做法是启用权重分片并在必要时启用梯度分片。基于 CUDA 的实现可以通过 NCCL 或自定义 memcpy-based all-gather 在不同互联场景下选择更优的通信方法,尤其在 PCIe 环境下,主机内存拷贝策略往往比 GPU 到 GPU 的直接通信更高效。 权重量化与持久量化(persistent quants)是提高低精度训练效率的关键。
训练过程中频繁的量化/反量化会消耗大量 CPU/GPU 周期并增加内存带宽压力,因此在某些场景下将量化后的权重常驻内存是优势。配合 offload 到主机内存的策略,可以在显存有限时仍保留量化权重的便利,并避免每步都重新量化。在实现上需要兼顾带宽与访问延迟,使用写合并(write-combined)内存或零拷贝技术可以在 PCIe 环境中提升总体吞吐。还可以把量化权重与主权重分开存储,主权重保留高精度用于更新,而量化权重用于前向/后向计算。 多卡并行方面,需要在多进程与多线程两种模式间权衡。多进程模式便于与 MPI 或 NCCL 集成,而多线程模式在单机场景下通过共享内存与 memcpy-based 通信可以实现更高的带宽利用率。
实现时应支持两种后端并提供一致的训练 API。通信算法上要提供多种选择,例如常规的 all-reduce、all-gather、all-to-all 以及基于 memcpy 的 send/recv 替代方案,以便在不同硬件拓扑与互联方式下选择最佳策略。结合 CUDA Graphs 可以进一步减少调度开销,但需注意图的构建粒度与动态控制流程可能带来的复杂性。 构建环境与依赖管理是工程化的第一步。实践经验表明,推荐使用 C++20 与 CUDA 12 或更高版本,配合 NCCL 用于设备间通信与 cuDNN 提供高效注意力算子。常见系统依赖包括合适版本的显卡驱动、libnccl、libcudnn 以及可选的 OpenMPI(如果采用多进程模式)。
构建系统通常基于 CMake,使用 Ninja 提升并行编译效率。为便于开发,可以将一些头文件级别的第三方库(如 JSON、CLI 工具、fmt、cudnn-frontend)通过 CMake 自动下载并集成,以减少手动配置。 数据准备与训练流程同样关键。训练前需要把文本数据 token 化并打包为训练与验证用的二进制文件。高效的数据加载器需要支持多文件通配符、按步读取与按需缓存,避免 GPU 因等待 IO 而闲置。训练流程应支持微批次和梯度累积策略,以便在显存受限时通过增加累积步数换取较大的有效 batch。
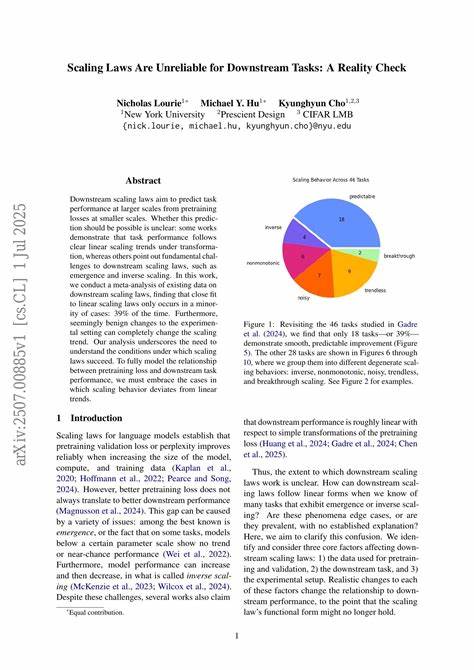
在训练调度方面,需要支持灵活的学习率调度(例如 cosine 或线性衰减)、warmup 与 cooldown 设置,以及常规的 Adam 超参控制。日志记录与模型保存策略要同时考虑调试与长期训练可恢复性,保存完整训练状态(包括优化器、学习率调度与随机种子)有利于中断恢复与持续训练。 性能基准可以帮助评估和调优实现。通过在不同显卡(如 RTX 4090、H100 或 L40S)和不同精度配置(bf16、fp8/e4m3)上测量 tokens per second(TPS)与理论峰值的比率(SOL),可以清楚地看到量化与分片策略带来的收益。实践中,在相同硬件上启用 fp8 或 e4m3 矩阵乘法通常能显著提高 TPS,但需在数值稳定性与训练质量上进行额外验证。对于大型模型,启用重计算与 offload 策略能在显存受限时保持训练进行,但会影响 TTB(训练到十亿 tokens 所需时间)与单步延迟。
实际工程中应综合考虑训练总成本、模型质量与时间预算,选择合适的折中方案。 测试与可靠性保障不能被忽视。重计算功能尤其容易引入数值差异,因此需要设计重计算一致性测试,比较在不同重计算设置下的损失与梯度范数,确保实现不会改变训练动态。固定参考测试与与 PyTorch/Transformers 的数值比对也能帮助捕获潜在 bug。为便于 CI,建议将核心测试通过 Python 绑定触发,使得在 CI 环境中可以用单元级的脚本快速验证 forward/backward 与优化器更新。 Python 绑定为工程提供了更高的灵活性。
尽管底层计算在纯 C++/CUDA 中完成,提供 coarse-grained 的 Python 接口可以让研究者在 Python 层控制训练循环、学习率策略或实验配置,同时避免频繁的 GPU-CPU 同步开销。绑定设计原则应是保持粗粒度操作,最小的单位为一次完整的 forward+backward+update,这样可以把复杂性限定在 C++ 层并确保性能。打包为 wheel 并发布预构建版本,可以降低入门门槛,方便在不同 CUDA 版本和硬件配置上快速部署。 在工程实践中,有若干优化建议值得注意。优先在内核级别优化内存访问模式,确保矩阵乘法与激活函数的内存对齐与 coalesced 访问。针对不同互联方式选择合适的通信策略,PCIe 环境下 memcpy-based all-gather 常常优于直接设备到设备通信。
在显存紧张时优先考虑重计算轻量级操作(如归一化与激活),而将大规模矩阵乘法的重计算作为最后手段。对于 offload,结合写合并内存或零拷贝技术通常能带来更好的 PCIe 带宽利用率。最后,对量化策略进行系统性验证,使用固定参考或与 PyTorch 对齐的测试来保证训练质量。 总结来说,在纯 CUDA/C++ 中实现量化 LLM 训练既是一项具有挑战性的工程任务,也是一种能够最大化硬件利用、降低训练成本的可行路径。通过细粒度的内存管理、灵活的重计算策略、权重与优化器状态的分片与 offload,以及为不同硬件场景设计多样化的通信算法,可以在单机多 GPU 环境中实现高效且稳健的训练系统。结合适当的测试、Python 绑定与预构建包,工程团队可以在保持性能的同时提升可用性与可维护性。
对于希望在有限资源上训练更大模型或加速实验迭代的团队,纯 CUDA/C++ 的量化训练方案提供了有吸引力的工程路径与实践指南。 。