近年来,人工智能智能体技术经历了飞速的发展,从最初的简单聊天机器人,逐步演变为具有高度自治能力的复杂系统。随着技术的进步,开发者不断探索更高效、稳定且易于维护的实现路径,流式SQL查询的引入为AI智能体的构建带来了新的思路和可能性。流处理平台如Apache Flink,正在成为智能体系统设计中的关键技术基础,以其极高的性能和扩展性,为实现智能体的实时数据驱动提供了坚实保障。 返顾软件工程领域,微服务架构的兴起鼓励模块化、专注一件事的设计理念。Seth Wiesman在Kafka Summit上的演讲“哦:那个微服务本应是一个SQL查询”引发了广泛关注,他提出将微服务以SQL查询的形式建立在流处理引擎之上的观点,强调这种方式在加快上线速度、保证数据一致性以及提升可伸缩性和低延迟方面的优势。将这一逻辑延伸至AI智能体开发,自然而然地引发了一个大胆设想:AI智能体是否也可以被构建为持续运行、事件驱动的流式SQL查询? 首先,明确AI智能体的定义对于理解建立途径至关重要。
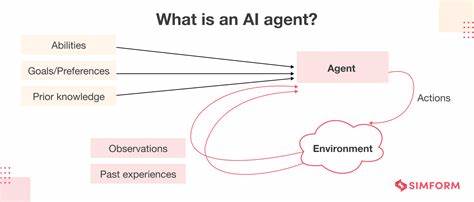
谷歌对AI智能体的定义强调其作为软件系统,能够运用人工智能技术实现目标导向,完成代表用户的任务,并具备推理、规划和记忆能力,同时拥有一定程度的自主决策和学习适应能力。在实际应用中,许多已部署的AI智能体实际上更多体现为由大语言模型(LLM)驱动的AI辅助工作流,输入数据经过处理、模型推理后输出结果。这一特征与微服务的输入处理和输出结果模式产生了天然的类比,也为SQL驱动智能体构建奠定了理论基础。 流式SQL查询与传统数据库查询最大的区别在于后者通常采取拉取数据的方式,执行一次查询即可获得完整结果;而流处理则是持续、推送式的,响应数据变化及时更新查询结果。这种连续、实时处理能力为智能体的事件驱动特性提供了理想支撑。通过Apache Flink等平台,开发者不仅能利用广泛的连接器生态(如Kafka、MQTT、关系型数据库等)实现数据流的无缝对接,还能借助内置的状态管理和高可用机制,保障智能体系统的稳定运行和水平扩展。
AI智能体与大型语言模型的交互是构建智能体系统的核心。流式SQL系统通过引入诸如CREATE MODEL和ML_PREDICT()等DDL语句和函数,使得在流处理环境中调用外部AI模型成为可能。举例而言,假设希望针对数据库和数据流领域的新研究论文自动生成摘要,利用类似OpenAI的GPT模型进行文本生成,只需注册模型并在SQL查询中调用,便可自动对新上传论文进行处理和摘要输出。这种方式充分利用了SQL的声明式优势和流处理的实时特性,极大地降低了构建复杂智能体的门槛。 事件驱动是企业级智能体尤为重视的属性。在数据流源源不断产生的场景下,如电子商务用户操作、工业传感器数据、数据库变更捕获等,智能体不依赖人工交互主动响应变化,完成库存自动补货、设备预维护等任务。
Apache Flink强大的连接器生态结合Kafka等事件平台,支持构建高内聚、低耦合、多智能体协作的系统架构。智能体之间通过事件总线,高效协作,完成复杂业务逻辑,而SQL则承担了关键的实时数据筛选、转换和逻辑判定任务。 智能体的上下文感知能力则依赖于对结构化和非结构化数据的高效整合。Flink SQL支持多流关联和查找连接,可以实时补全客户信息、订单背景等结构化上下文信息。此外,针对文档、知识库等非结构化数据,检索增强生成(RAG)成为主流方案,借助向量数据库存储领域知识的向量表示,智能体在调用LLM生成响应时载入最新且精准的领域信息。这一切都得益于Flink支持的丰富数据类型,及通过自定义函数(UDF)实现的向量搜索查询能力。
内存管理对于智能体来说同样重要。智能体需要“记忆”过去的交互或事件以构建上下文,提升推理质量。Apache Flink提供的Process Table Functions(PTF)作为增强型用户定义函数,为状态管理和有状态流处理提供了灵活解决方案。通过PTF,智能体可以存储和检索对应会话或用户的历史数据,实现持久化、分布式的智能体“记忆”,并支持对长时任务进行状态追踪和恢复,从而大幅提升智能体系统的鲁棒性和扩展性。 然而,SQL的声明式范式限制了智能体在复杂推理或动态决策中自由度的发挥。虽然流式SQL在数据预处理、聚合和分发方面表现出色,但面对需要多轮交互、多模型调度、工具调用等更“智能”的行为时,单纯的SQL已难以胜任。
为此,许多团队正努力通过扩展机制,如PTF嵌入复杂Java逻辑,集成Model Context Protocol(MCP)标准,实现智能体调用多样外部服务和工具的能力,将SQL的优势与通用编程语言灵活性相结合。 在Apache Flink社区,由Confluent和阿里巴巴等团队发起的Flink Agents子项目(FLIP-531)正是迈向智能体专用运行时的重要尝试。该项目旨在基于Flink的底层流处理能力,打造支持Java和Python的智能体框架,集成工具链、向量搜索与智能体间通信功能,为开发者提供构建端到端自适应智能体的全新路径。这不仅继承了先前Stateful Functions项目中对状态管理和分布式执行的经验,也借助AI技术栈的蓬勃发展,为智能体应用的普及提供了广阔空间。 总的来说,Apache Flink结合其强大的流数据处理能力和日益完善的AI集成方案,正在成为企业级智能体时代不可或缺的基础平台。通过SQL驱动,更多熟悉数据操作的开发者能够以声明式方式快速构建、部署智能体,显著降低了创新门槛。
结合事件驱动架构、上下文增强和状态管理机制,智能体系统能够实现高效、稳定且灵活的实时决策,满足工业、金融、医疗、零售等多领域的应用需求。 当然,将所有AI智能体都构建为流式SQL查询并非必然选择。不同应用场景对智能体的复杂度和自由度有不同要求,合理地结合SQL与代码实现,是迈向智能体实用化的关键。未来随着社区推动的智能体专用运行时逐步成熟,开发者将拥有更丰富的工具和框架,打造真正意义上的自主智能体,赋能各类业务场景。 回顾这场关于“智能体为何可以甚至应当用SQL来实现”的思辨,我们看到的不仅是一种技术实现方式,更是一场理念的革新。SQL不再只是传统数据库的查询语言,而是在流处理和AI模型交汇的新领域中发挥出强大生命力和广泛适用性。
不论是为加速AI智能体落地的企业,还是为普及智能化能力提供便利的数据工程师,流式SQL的出现无疑开启了一个前所未有的智能化新时代。