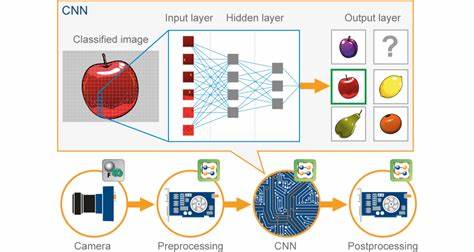
人工智能(AI)图像识别技术正日益融入我们的日常生活,从智能手机的面部解锁到自动驾驶汽车的环境感知,图像识别技术发挥着关键作用。随着深度学习的发展,尤其是卷积神经网络(CNN)的出现,AI图像识别的准确率和效率获得了极大提升。理解这些技术是如何实现的,能够帮助我们更好地把握未来技术的发展方向。 图像识别是指计算机系统对输入的图片或视频帧进行分析,识别出其中的物体、场景或特征的过程。传统的图像处理方法多依赖于手工设计特征提取算法,如边缘检测、角点检测等,然而这些方法在复杂环境和多样化场景下表现有限。深度学习特别是CNN的引入,使得计算机能够自动学习和提取视觉特征,极大地提升了图像识别的能力。
卷积神经网络是受生物视觉皮层启发设计的一种深度学习模型,专门用于处理网格状数据如图像。CNN通过卷积层提取图像的局部特征,池化层进行降维和压缩信息,最终通过全连接层进行分类和预测。这种层级结构使得模型能够捕捉从低级边缘、纹理到高级语义的多层次特征,显著提高了图像识别的表现。 在CNN中,卷积操作是核心。它计算滤波器与输入图像区域的点积,从而提取特定的特征,如边缘、角点。多个卷积滤波器组合可以构建丰富的特征图,反映图像中的各种细节。
接着,池化操作通过最大值或平均值的方式缩小特征图的尺寸,减少计算负荷并增强模型的鲁棒性。 训练CNN模型需要大量的标注图像数据。通过反向传播算法和梯度下降优化,模型不断调整其内部参数,以最小化预测结果与真实标签之间的误差。随着训练的深入,模型能够识别出更加复杂和抽象的图像特征。近年来,利用大规模数据集如ImageNet训练的深度CNN模型,已经在图像分类和目标检测等任务中达到甚至超越人类的水平。 AI图像识别技术在多个行业展现出广泛应用价值。
在医疗领域,计算机辅助诊断系统通过识别医学影像中的异常结构,提高疾病早期检测的准确性和效率。在自动驾驶领域,车辆依赖图像识别技术实现对周围环境的实时感知,保障行车安全。电子商务平台则通过图像搜索功能,提升用户购物体验,实现精准商品推荐。 尽管图像识别技术取得了巨大进展,但仍面临多项挑战。一方面,模型对图像的光照、角度变化以及遮挡等因素较为敏感,导致识别准确度下降。另一方面,模型的计算资源消耗较大,限制了其在移动设备上的应用。
未来研究致力于开发更加轻量化、高效且鲁棒性强的算法,同时结合多模态数据融合,进一步提升图像识别的智能化水平。 除了传统CNN,目前越来越多的新型架构如残差网络(ResNet)、注意力机制和变换器模型(Transformer)等被引入图像识别领域。残差网络通过引入跳跃连接解决了深层网络训练中的梯度消失问题,使得网络可以更深、更复杂。注意力机制帮助模型聚焦于图像的关键区域,提高识别的准确性和解释性。变换器模型则打破了卷积局限,利用全局信息进行图像特征提取,正在成为视觉任务的研究热点。 算法的不断革新带动硬件的发展,专业的AI芯片和加速卡如GPU、TPU的出现,使得训练和推理过程大大加快。
边缘计算和云计算的结合,使得图像识别技术能够实时响应,满足不同应用场景的需求,同时保障数据隐私和安全。 未来图像识别技术将进一步融合自然语言处理、多模态学习和强化学习,实现不仅“看懂”图像,更能够“理解”和“解读”图像内容,提供更智能、更人性化的服务。例如,自动驾驶中的环境感知将不仅仅是识别物体,还能推断对象的意图和行为;医疗影像分析将结合患者临床信息,实现个性化精准诊疗。 总之,人工智能图像识别技术正处于快速发展阶段,卷积神经网络作为其核心技术,为我们打开了理解和应用视觉信息的新大门。随着技术的不断进步和应用场景的拓展,图像识别将在更多领域释放巨大潜力,推动社会生产生活方式发生深刻变革。对这一领域的持续关注和深入研究,将为未来智能时代的到来奠定坚实基础。
。