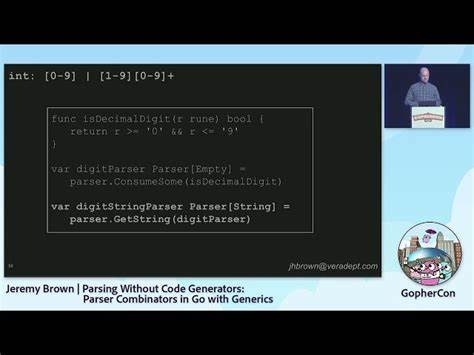
随着人工智能技术的迅速发展,特别是大型语言模型(LLMs)在自然语言处理和代码生成领域的突破,竞赛编程领域的应用需求也日益增长。LiveCodeBench Pro作为一款专门针对竞赛编程能力进行综合评价的工具,受到业界和学术界的广泛关注。尤其是由奥林匹克竞赛奖牌得主主导的评测体系,进一步提升了对模型表现的专业评价标准,使这一工具在竞争激烈的编程领域中脱颖而出。LiveCodeBench Pro不仅单纯依赖自动化评分,而是结合了顶尖算法人才的深度洞察,通过多个维度对大型语言模型进行系统化的性能分析,为模型优化和应用提供了不可或缺的指导。竞赛编程不仅考验选手解决问题的思维模式,也考察算法设计、代码执行效率及正确性等多个层面。传统评测多以自动判题系统为基础,存在评分单一、误判概率等问题。
LiveCodeBench Pro创新引入由奥林匹克奖牌级选手组成的评审团队,他们凭借多年竞赛经验,能够更准确地理解题目难度和实际表现之间的关系,从而为大型语言模型的代码提交提供更为精准的评级,特别是在Codeforces等主流竞赛平台的Hard、Medium和Easy三大难度梯度上实现差异化评估。这一过程涵盖模型代码的正确性验证、算法实现的合理性分析以及代码风格的综合评价。通过评审团队的细致审查,模型在不同难度问题上的解题策略和表现被详细记录于LiveCodeBench Pro的平台中。平台支持动态查询与跟踪模型评分趋势,帮助研究人员观察模型在多个季度的表现变化,了解其在持续迭代过程中性能的提升或瓶颈。与此同时,数据表格中显示的信息如Codeforces的评级和通过率,直观展示了模型在Hard、Medium、Easy三个难度等级上的成绩及其整体综合表现,排序依据先难后易,再综合评分,使得比较更加科学合理。奥林匹克竞赛奖牌得主在评判过程中,特别注重模型的创新算法使用及其效率表现,他们不仅关注解题是否正确,更看重代码解决复杂问题的能力和时间空间资源利用率,这一点是此前单纯依赖自动测评难以比拟的。
LiveCodeBench Pro的设计理念强调“评测即学习”,奖牌得主通过给出的反馈,促使开发者能够针对性地提升模型的代码生成能力,弥补普遍存在的易错点和低效实现,促进大型语言模型在竞赛编程中的实用化和智能化。在未来,随着更多竞赛高水平人才参与评测体系,以及人工智能技术持续创新,LiveCodeBench Pro有望成为连接人工智能研究与编程竞赛实践的桥梁,不断推动代码智能生成向更加精准和高效方向发展。通过该平台,模型研发者不仅能得到高质量的性能反馈,还能借助奖牌得主的专业指导进行策略调整,整体提升竞赛编程解决方案的水平。此外,LiveCodeBench Pro的可视化趋势分析工具增强了用户体验,让技术人员能快速把握模型运行的优缺点,针对性制定优化路径。竞赛编程对逻辑推理和计算复杂性的考验极为严苛,正因如此,奥林匹克级程序员在LiveCodeBench Pro中的参与和主导意义非凡。他们的丰富经验为评判标准注入了深厚的权威性和科学性,确保评分的公平性和专业性。
随着AI模型在代码生成领域的不断进步,评测领域也必须紧跟步伐,LiveCodeBench Pro恰好满足了这一需求,成为业内认可的高标准评价系统。如今,越来越多的研究者和开发团队将目光投向此平台,借助奖牌得主的见解来定义和验证未来程序生成模型的能力边界。在这样一个数据与智能深度融合的时代,如何科学、准确地评价一个拥有巨大潜力的代码生成模型,成为推动技术前进的关键。LiveCodeBench Pro通过其创新的方法论和权威的专家评审机制,将人工智能生成代码的评测推向了一个新的高度。它不仅是评估工具,更是竞赛编程领域智能化变革的重要推动力。