大型语言模型(Large Language Models, LLMs)作为人工智能领域的革命性技术,已经广泛应用于自然语言处理、内容生成、智能助理、教育、商业报告撰写等多个领域。随着应用需求的多样化,用户常常需要模型同时响应和执行多条指令。然而,LLM究竟能够同时遵循多少条指令,其表现将如何随着指令密度变化而改变,仍然是前沿研究的热点课题。理解大型语言模型多指令执行能力,能够帮助我们更好地设计交互方式,提升模型在实际应用中的可靠性和效率。近期发布的论文《How Many Instructions Can LLMs Follow at Once?》为我们提供了宝贵的实验数据和分析视角。该研究首次系统性地评估了超过500条指令同时存在时,模型的执行准确率及其变化趋势。
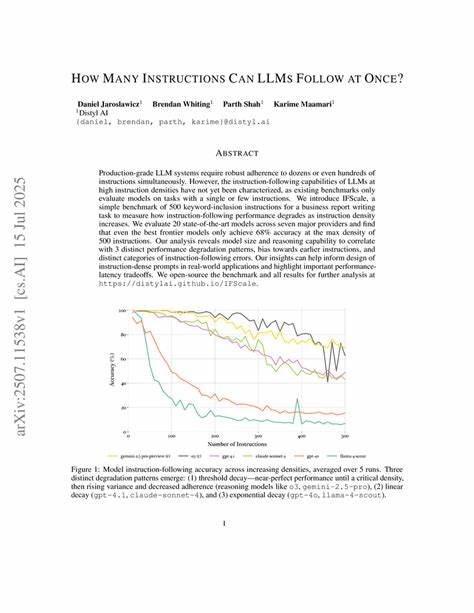
研究团队设计了IFScale基准测试,将500条关键词指令融入到商业报告写作任务中,从而模拟高度密集指令场景,并涵盖了20款主流先进模型进行横向比较。研究结果显示,即便是当今最先进的模型,在最大指令密度下的准确率也仅达到68%,这意味着随着指令数量激增,模型的执行准确率呈现出明显下降的趋势。一个核心发现是模型的参数规模和推理能力与其多指令执行表现密切相关。较大规模和具备更强推理能力的模型往往表现出更强的指令耐受度和执行一致性,能够更好地管理并折中不同指令之间的冲突或优先级问题。此外,研究指出模型通常偏向遵循早期指令而忽略后续指令,这种“序列偏好”现象揭示了当前模型在多任务整合与指令管理方面的先天限制,也是未来优化的重点方向。不同类型的指令错误呈现出多样化特点,包括关键词遗漏、指令执行顺序错乱、指令冲突处理不当等。
掌握这些错误模式有助于开发者设计更合理的多指令提示,更有效地规避性能瓶颈。除了技术层面的考察,论文还探讨了实践应用中的性能与响应延迟之间的权衡。高指令密度下,为保证模型准确执行通常需要额外计算资源和处理时间,如何在保障响应速度的同时提升指令遵循度,是实现大规模工业级应用的关键难题之一。基于IFScale基准测试的开源结果和工具,为学术和工业界研究人员提供了宝贵资源。他们可以据此深入分析模型行为,调优模型结构,设计符合特定业务需求的指令架构,推动LLM在更复杂真实场景中的应用落地。回顾当前技术发展,虽然大型语言模型已具备强大语言理解与生成能力,但要实现真正高效无误的多指令并行执行,仍面临诸多挑战。
未来,融合更精细的指令解析模块、增强模型的元认知能力、采用分层指令处理策略或许将成为突破点。同时,跨模型合作、多模态数据融合也有望提升模型处理复杂需求的灵活性与可靠性。从实际应用角度来看,对于开发者和产品经理而言,理解模型多指令执行能力的局限性,合理设计任务指令、分段简化需求至关重要。完善的 prompts 设计和指令管理机制,不仅能显著提升任务完成质量,还能避免因指令密度过高带来的执行錯误,确保用户体验和系统稳定性。综上,如何平衡指令数量与模型性能,是推动大型语言模型广泛应用的核心命题。IFScale基准测试为我们揭示了当前技术的瓶颈与潜力,也昭示了未来研究方向。
紧随技术演进,结合多学科方法不断优化,多指令执行能力必将显著提升,助力实现更智能、更高效、更可靠的人工智能服务。