在现代编程语言设计中,变量绑定机制是语言表达能力与执行效率的关键因素。特别是在涉及复杂数据流和并行计算的场景中,绑定的结构和语义直接影响着程序的可读性、灵活性以及性能表现。本文将围绕树绑定(Tree Bindings)与有向无环图绑定(DAG Bindings)展开深入探讨,分析二者在流式编程语言中所体现的不同特点和应用意义。树绑定与DAG绑定代表了两种截然不同的变量作用域和依赖关系管理模式,对理解这一点有助于程序员更好地驾驭现代流式和函数式编程范式。树绑定的核心在于变量的作用域以严格的层次结构组织,类似于一棵树的形态。每个绑定节点都只能有一个直接的父绑定,这种方式自然映射了传统的词法作用域和嵌套结构,极大地方便了程序的静态分析和理解。
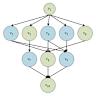
树绑定的优势在于清晰的作用域层级,简化了变量查找的流程,并且有助于维护代码的结构化,降低理解难度。然而,这种绑定方式限制了数据流之间的动态交互,尤其是在需要复杂依赖管理或并行执行的场景下显得较为僵化。在流式编程中,如Qi语言所体现的场景,使用树绑定时复杂流程会展现出隐含的顺序依赖,这种依赖阻碍了分支之间的并行计算。举例来说,当多个计算分支依赖于前一个分支的绑定变量时,后续分支必须等待前者完成,导致执行效率受限。相比之下,有向无环图绑定允许变量绑定形成更复杂的依赖关系网络。每个变量绑定节点不再仅限于单一父节点,而是能够接纳多个输入和输出,构成一个无环结构。
这为表示多个相互独立或部分依赖的计算流程提供了极大便利,使得程序可根据真正的依赖关系进行优化与并行调度。通过DAG绑定,开发者可以明晰地表达依赖关系,避免隐式强制的顺序执行,从而提升计算的并行度和整体执行效率。特别是在现代多核处理和分布式系统环境中,这种绑定机制成为实现高性能流式处理的重要技术基础。在Qi语言的流式示例中,利用DAG绑定的思想可以消除对分支执行顺序的隐式依赖,使各分支能够独立计算,同时维持对后续流程的变量绑定传递。尽管DAG绑定提升了灵活性,但它也带来了管理复杂性的增加。变量作用域和绑定关系不再遵循简单的树形结构,程序解析和错误诊断难度提升,需要语言设计者在语法和工具链层面提供更强的支持。
此外,DAG绑定的实现通常涉及更复杂的运行时检查和调度逻辑,也对语言运行环境提出了挑战。结合实际应用来看,树绑定依然适合大多数传统编程范式和简单的顺序逻辑场景,它保证了变量作用域的安全性和易用性。而在需要高度并行、复杂依赖管理或数据驱动计算的现代编程需求中,DAG绑定显然具有不可替代的价值。对开发者而言,理解并合理选择二者间的绑定模式,将直接影响代码的性能可扩展性和维护成本。对语言设计者来说,探索将两者优势兼顾的混合绑定策略,以及完善的语义定义和编译器支持,是推动编程语言演进的重要方向。近年来,随着流式编程模型的兴起,像Qi语言这样强调数据流隐式传递和绑定的工具正逐步受到关注。
其通过将传统的树绑定约束转化为更自由的DAG依赖结构,为复杂应用提供了新的思路和可能。程序员通过灵活使用绑定标识符,并明确表达依赖关系,能够在保持代码简洁的同时,实现更高效的执行路径。可以预见,随着硬件多核化和分布式计算的持续发展,DAG绑定的理念将成为提升编程语言竞争力的关键所在。综上所述,树绑定与有向无环图绑定分别代表了编程语言中变量作用域管理的两极。一边是传统、简洁且易于理解的树形结构,另一边是高效、灵活但复杂度较高的DAG结构。认识到两者的本质差异及应用场景,能够引导开发者和语言设计者更好地调整设计思路,兼顾代码可维护性与性能优化,推动编程实践迈向新高度。
持续关注相关开发社区和语言版本更新,将为掌握和利用最新绑定机制提供宝贵助力,推动技术创新和程序设计理念的发展。