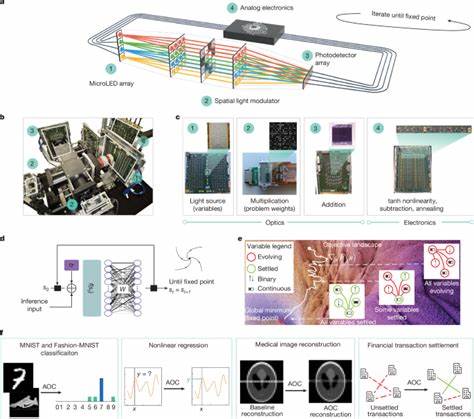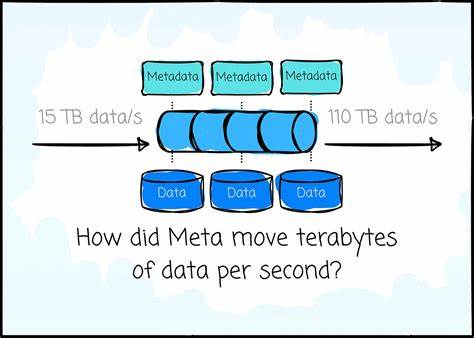
随着数字化时代的到来,数据量呈爆炸式增长,Meta作为全球最大的互联网公司之一,每天面临着数以亿计的用户活动产生海量数据。这些数据不仅种类繁多,来源复杂,还需要以极低的延迟实时传输至各种数据处理系统。为应对这一挑战,Meta研发了名为Scribe的消息队列服务,能够实现每秒数十甚至上百TB数据的高效传输与分发。Scribe的设计和实现体现了Meta在大规模数据基础设施领域的领先创新,为实时数据流的管理树立了新的标杆。Scribe的核心使命是支持多个异构数据源将海量信息安全、稳定地写入系统,同时满足多样化的消费需求。系统采用多跳写入路径设计,使数据通过多个中转节点流转,利用缓冲机制和非确定性的路由策略,大幅提升写入的可用性和容错能力。
这样的设计避免了单点瓶颈,有效支持数亿级别的生产者同时高效持久化数据,保证数据完整性和流畅传输。对于读端,Scribe提供高度灵活的副本数据放置和表现形式,依据实时的访问负载动态调整副本分布,最小化资源消耗,提升流量调度效率。多租户架构保证了各类数据流能在共享基础设施上互不干扰,访问隔离且具备弹性。Scribe的设计还深度考虑了不同应用场景的需求差异,提供多种消息传递和顺序保证级别,满足从严格顺序消费到高吞吐无序传输的多样需求,确保系统兼具灵活性和一致性。Scribe在处理全局级别的读端分发上展现出极强的扩展能力,支持数百甚至上千的消费者跨多个数据中心同步订阅同一逻辑数据集。读取端能够高效筛选所需数据子集,减少无谓的反序列化开销,实现"无ETL"(Extract, Transform, Load)数据消费,提升实时分析和机器学习模型训练的速度和准确性。
Meta的海量数据实时传输管道正是依靠类似Scribe这样高度可靠且灵活的消息队列服务,确保从数据生成到处理再到应用呈现的整个链路保持高速、稳定和低延迟。Scribe经过18年的演进,结合丰富的业务实践,不断优化在多任务、多租户环境下的流量控制与资源分配策略,有效保护关键业务的性能,防止资源争抢导致的服务波动。未来,随着数据规模的持续扩大和实时处理需求的多样化,Scribe将持续发挥核心作用,驱动Meta乃至行业内大数据处理架构的升级与创新。综上所述,Scribe不仅是Meta应对海量数据实时传输挑战的利器,更代表了当代数据基础设施向规模化、智能化方向迈进的关键技术里程碑。在云计算和人工智能大潮下,类似Scribe这样兼顾高吞吐和低延迟的系统设计理念,无疑将为更多企业和应用提供宝贵的经验与借鉴,推动数据驱动决策和智能服务的普及与深化。 。