在当今计算机技术飞速发展的背景下,多线程并发编程成为提升应用性能和响应能力的关键手段。然而,传统的多线程同步机制如互斥锁(mutex)和读写锁(reader-writer lock)往往会带来性能瓶颈,尤其是在读操作远多于写操作的场景中。针对这一挑战,Read-Copy-Update(简称RCU)作为一种高效的同步策略应运而生,受到越来越多开发者和系统设计者的关注。RCU不仅能够显著提升读取性能,还能通过巧妙的设计保证数据结构访问的一致性和安全性。本文将从多个层面深度剖析RCU,探讨其核心原理、实际应用以及与其他同步机制的对比,助力读者掌握这项先进技术。首先,RCU是什么?它是一种多线程同步机制,旨在避免使用传统的锁机制,让多个线程可以同时读取和更新共享数据结构,而不会发生不一致或崩溃。
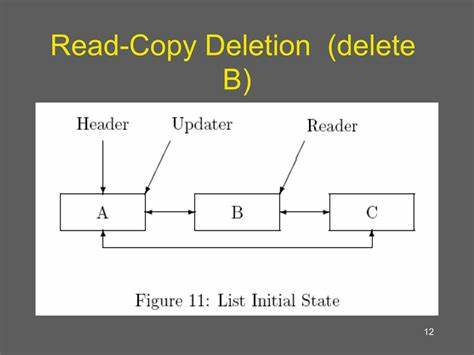
其核心思想是将写操作与读操作解耦,通过“读先拷贝,更新后替换”的方式保证所有读者访问到的要么是旧的数据结构,要么是新结构,但绝不会出现中间不一致的状态。具体来说,当需要修改某个共享数据结构时,写线程会先复制当前数据,完成修改后将原有指针切换到新版本,同时保证所有正在进行中的读线程访问完旧版本后才回收旧数据。这种设计使得读操作完全无锁,从而极大提升读取的效率和并发性,而写操作则通过延迟回收和同步机制保证安全。RCU的设计理念源于空间与时间的折中:通过增加内存空间存储多个数据版本,换取高速且无阻塞的读取体验。特别是在读多写少的负载环境下,RCU的优势尤为明显。随着C++标准不断演进,RCU在现代C++中的支持也逐步完善。
最新的C++26提案中引入了一套RCU接口,包括rcu_obj_base类、rcu_domain类及一系列函数如rcu_synchronize、rcu_retire等,简化了RCU在C++项目中的集成和使用。同时,RCU的使用也分为不同类型,如侵入式RCU(intrusive RCU)和非侵入式RCU(non-intrusive RCU)。侵入式RCU要求数据类继承自特定基类以实现跟踪保护,这种方式通常性能更优;而非侵入式RCU则通过外部机制实现数据保护,适合对类结构无法修改的场景。此外,同步RCU(synchronous RCU)则更多用于需要显式等待保护区域释放的情况。如何选择适合的同步机制?这是许多程序员关心的问题。一般来说,当程序读操作远多于写操作时,RCU凭借其锁的最小化优势,是替代读写锁的理想选择。
相比之下,危害指针(Hazard Pointers)则更适合替代引用计数,在内存管理和安全回收上表现强劲。RCU和危害指针的对比从根本上体现了不同同步策略对多线程管理的不同思路和设计权衡。值得注意的是,虽然RCU极大提升了读取效率,但写操作的复杂性和内存开销需要开发者慎重权衡。RCU要求写线程分配新的内存副本,并在一定延迟后回收旧版本,这增加了空间消耗,也需要配合合理的同步机制确保数据安全。对于高写负载场景,RCU可能并非最佳选择。RCU的实际应用涵盖操作系统内核、数据库系统和高性能服务器等多个领域。
在Linux内核中,RCU被广泛用于实现高效的读多写少数据结构访问,确保系统高吞吐率和响应时间。现代数据库系统借助RCU实现多版本并发控制(MVCC),优化查询性能。与此同时,随着C++26标准将RCU接口纳入标准库,普通应用程序开发者也可以更便捷地使用RCU,提高多线程应用的性能表现。在具体编码实践中,使用RCU需要掌握相关接口和同步语义。首先,定义受保护对象通常使用rcu_obj_base作为基类;通过rcu_domain划分保护区域,管理读写的生命周期。读线程通过scoped_lock绑定到rcu_domain实现安全访问,写线程则利用rcu_retire安排对象延迟销毁,并通过rcu_synchronize等待所有读访问结束。
整个过程中,程序员需要关注对象的生命周期管理,确保无悬挂指针和内存泄漏风险。正因如此,RCU的学习曲线相对陡峭,使用不当可能导致难以察觉的并发错误。所以,在采用RCU之前,深入理解其原理和限制尤为重要。总结来看,Read-Copy-Update作为一种高效的多线程同步解决方案,以其无锁读取和一致性保障的设计理念,显著提升了多线程环境下的数据访问性能和可靠性。它特别适合读操作频繁而写操作较少的场景,是读写锁的有力替代。随着C++26对RCU的内置支持和文档完善,越来越多开发者能够将其引入实际项目,提升并发程序的性能瓶颈。
未来,随着多核处理器的普及和并发需求日益增长,RCU作为一项核心技术,将为软件开发带来更多创新与突破。理解精通RCU,不仅提升代码效率,更是迈向现代高性能编程的重要一步。