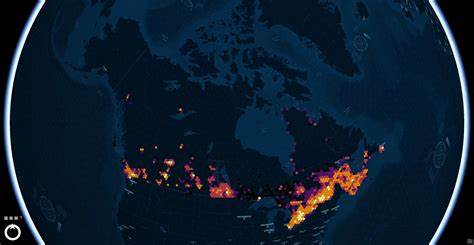
加拿大正在进入一个以开放空间数据为核心的时代,统计加拿大(Statistics Canada)近期发布的开放建筑数据库 ODB(Open Database of Buildings)将近乎国家级的建筑足迹资料收集汇编成一个可供研究与应用的资源。这个数据集包含约14,417,429栋建筑,其来源横跨530个数据集、来自107个政府机构,覆盖从联邦、省级到市政的小范围数据源,呈现出前所未有的地理覆盖深度和数据多样性。对城市规划者、应急响应人员、能源分析师与空间数据开发者而言,这既是机遇,也是挑战。本文围绕数据概况、处理实践、质量分析、与其他数据集的比对、典型应用场景与改进建议展开讨论,以帮助读者理解并有效利用加拿大的开放建筑数据。 开放建筑数据库的构成与处理思路首先要了解数据的来源与组织方式。统计加拿大将数据按省和地区打包为 GeoPackage(GPKG)格式,并在发布前进行了清洗与整合。
原始发布文件体量较大:压缩后约2.5 GB 的 ZIP 包,解压后约6.2 GB 的 GPKG 数据,经过重新投影、空间排序与列清洗后,被转换为高效的 Parquet 存储格式并压缩为约1.8 GB,以便在现代分析平台中高速读取与可视化。转换流程中常用到的技术包括 GDAL 用于投影与格式转换,DuckDB 及其空间扩展用于批量转换与统计,Parquet 与 ZSTD 用于列式压缩与传输优化,Hilbert 或 H3 编码用于空间排序与聚合加速。这样的工程实践不仅提高了数据加载效率,还能显著降低云存储与网络传输成本。对于需要在 QGIS、ArcGIS Pro 或云端进行地图渲染与分析的团队,这类优化是必要前置工作。 数据质量与字段覆盖是评估可用性的关键维度。ODB 在元数据字段中包含地址、建筑用途、楼层数、高度、建筑面积、建成年份、来源标识等常见属性,但这些字段的完整性差异巨大。
其中地址字段约有三成可用,楼层数与高度、建成年份等字段的空缺率甚至更高。具体而言,楼层信息的覆盖率不足,只有约38万条有楼层记录;高度字段存在大量异常值与占位符(例如接近100米的占位数值),而建成年份字段大多数为空或包含非标准文本(如 CIRCA、PRIOR 等)。用途字段虽然涵盖了从住宅、商业到特殊公共建筑的分类,但约有1200多万条记录未被分类。这样的缺失与不一致主要源自数据的异构化,市政与地区在采集与编码时不统一格式、单位与语义。 来源维度体现了 ODB 的优势与复杂性。数据集中既有"Government of Canada"与省级机构的大量贡献,也包含数十个市政与地区分发的局部数据。
多伦多、卡尔加里、渥太华、埃德蒙顿等大城市的数据覆盖稠密,而某些偏远或小型镇区则由少量地方政府或根本缺失采集。统计显示,数据集中前几名的来源贡献了大量建筑要素,但来源数目长尾显著,许多小机构只贡献数千甚至数百要素。地方性差异导致属性质量起伏明显。例如卡尔加里的建筑用途字段相对完善,但其建成年份几乎全部为空。边界归属总体准确,省界与边界邻接地带的建筑被正确标注,这对跨省的空间分析非常重要。 与 OpenStreetMap 等其他开源数据进行对比,可以发现各有优劣。
OSM 在社区参与式编辑方面持续保持活跃,某些偏远地区由热心社区长期维护,可能覆盖 ODB 缺失的聚落如北部的部分城镇。然而 OSM 的属性结构更加自由,建筑用途与高度等字段的标准化程度参差不齐。另一方面,私有或学术项目如 PSC 与 Layercake 发布的建筑要素在全球一致性与更新频率上也有优势,但各自的覆盖范围与汇编策略不同。综合来看,没有单一数据源能够覆盖加拿大所有建筑,最佳实践是将 ODB 与 OSM、PSC 等数据融合,通过空间覆盖与属性匹配互补不足,进而形成更为完整的国家级建筑库。 实际应用场景非常广泛。在城市规划与土地利用分析方面,建筑足迹能够为地块密度、建筑覆盖比(BCR)、绿地渗透率与交通能达性等指标提供基础数据支撑。
在住房政策与社会服务配置层面,地址与单位数信息(当可用时)有助于估算居住人数、住宅单元分布与社区脆弱性。在应急响应与灾害管理中,完整的建筑足迹配合楼层与用途信息可以用于评估暴雨淹水、火灾与地震的暴露量和潜在影响。能源与碳排放模型也依赖建筑面积、楼层与高度等属性来估算供暖需求与建筑能耗谱。对于商业分析与物流规划,细致的建筑边界支持门址级定位、最后一公里配送优化以及细分市场分析。即便属性不全,建筑几何本身也能为许多空间模型提供重要输入。 尽管机会众多,但必须直面几个显著挑战。
属性缺失与格式不一致是首要难题。要将 ODB 用于精细化建模,往往需要对建成年份、楼层与高度进行外推或与第三方数据交叉验证。地址字段虽然在约三成记录可用,但存在将多个单元拼接为一个字符串的现象,需采用地址解析与正则清洗技术将其拆分成规范的门牌与单元号。高度字段的异常值需要规则化处理或采用替代数据源(如激光雷达 LIDAR、高分辨率立面信息)进行回填。另一个挑战是数据更新频率与授权许可,尽管 ODB 为开放数据,但不同来源的更新节奏可能不一致,合并后需要建立版本管理与增量更新流程。隐私与合规也不可忽视,尤其当建筑与地址信息与人口统计或税务数据结合时,需要遵守相应的数据保护法规。
为应对上述挑战,提出若干实务建议。首先应建立一个基于空间索引的多源融合框架,优先按质量分级选择数据源,使用空间重叠与属性相似度进行配准,必要时采用机器学习方法通过邻域特征推断缺失属性。其次标准化属性编码体系,指定统一的楼层、用途、建成年份与高度的编码规则,并开发自动化清洗管道处理常见占位符与非结构化文本。再次在存储与检索方面采用列式压缩格式如 Parquet,加上空间排序(Hilbert 或 H3)以优化云检索性能与并行查询效率。可视化阶段建议使用 QGIS 或商业 GIS 工具结合切片服务来高效渲染超过千万要素的热力图与聚合图层。最后建立公开的质量报告与元数据追踪,记录每个要素的来源、采集时间与处理步骤,确保用户在下游应用中理解数据的局限性。
从技术实现角度来看,构建可重复的处理流水线至关重要。推荐采用可重现的数据管道工具链,包含数据下载、投影转换、拓扑清洗、属性标准化、空间排序与压缩打包等环节。对大型建模与可视化任务,提前进行空间分区与行组优化可以显著提升查询与导出速度。对于需要全球唯一标识的应用场景,生成稳定的不变 ID 并保持与原始来源 ID 的映射关系能够在后续更新和溯源时节省大量成本。 展望未来,随着更多市政与省级机构开放其建库数据,以及社区持续补充 OSM,构建一个动态更新、跨源融合的加拿大建筑知识图谱并非遥不可及。结合遥感数据、地籍信息与实时传感网络,可以进一步丰富建筑属性层级,提升用于灾害响应与城市数字孪生的精度。
同时,建立社区化的质量审核机制与开放标准将有助于降低整合成本,推动科研、政府与产业界的协同创新。 结语加拿大的开放建筑数据库是一次重要的数据基建投资,为研究与决策提供了前所未有的空间基线。要充分发挥其价值,需要跨学科的工程实现、严格的数据治理与持续的社区参与。面对14.4百万条建筑足迹,数据从覆盖到可信的旅程仍在继续,但通过合理的处理策略与多源融合方法,可以把这些散落的几何与元数据转化为支持智慧城市、韧性规划与可持续发展的强大资产。愿从业者与研究者在理解其局限的同时,积极实践与贡献,推动加拿大建筑数据的质量与应用走向成熟。 。