近年来,人工智能技术的快速发展推动了语言模型规模和能力的不断提升。作为领先的AI研究团队,Qwen团队于2025年推出了其最新旗舰模型 - - Qwen3-Max。这款基于超过一万亿参数的超大规模预训练模型,不仅在技术上实现了历史性突破,也在多项行业应用中展现出强大的实用价值。Qwen3-Max代表了当前AI模型从"力量叠加"向"智能飞跃"的转折点,开启了人工智能应用的新纪元。Qwen3-Max诞生于Qwen3系列技术积累的结晶,延续并创新了其独特的架构设计理念。该模型采用了Mixture of Experts(MoE)专家混合机制,极大提升了参数利用效率和训练稳定性。
值得一提的是,Qwen3-Max在训练过程中实现了持续平稳的损失曲线,无需传统的训练回退或复杂数据分布调整,保持了训练的高效与顺畅。背后依托的PAI-FlashMoE多级流水线并行策略,优化了训练中的资源利用率,使得模型在大规模集群环境下表现出色。这些创新不仅提升了整体训练效率,MFU(模型浮点操作利用率)较前代产品提升30%,更针对超长上下文优化了ChunkFlow技术,实现了最大1百万token的上下文处理能力,极大推动了长文本理解与生成的界限。Qwen3-Max同样在实际应用场景中表现优异。其预训练数据涵盖超过36兆亿token,确保了模型的广泛知识覆盖与多语言理解能力。Qwen3-Max-Instruct版本尤其突出,其在国际权威的Text Arena排行榜上位列第三,超越了诸如GPT-5等竞品。
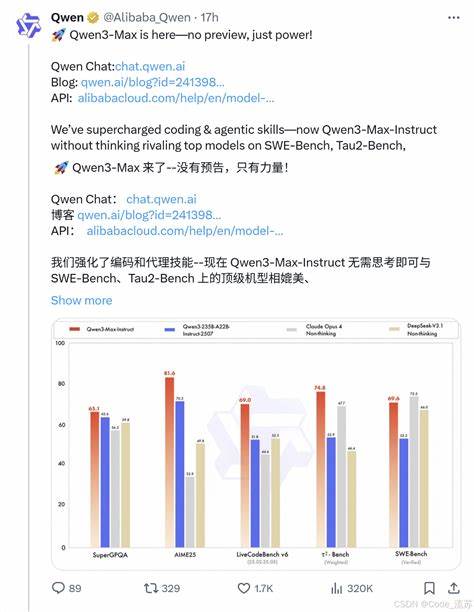
在编码能力方面,Qwen3-Max-Instruct凭借69.6分的优异成绩问鼎SWE-Bench Verified测评,这是一项针对真实世界编程挑战的高难度测试。模型拥有卓越的代码理解与生成能力,为开发者提供了强有力的技术支持。在智能代理任务中,Qwen3-Max-Instruct同样领先,Tau2-Bench测试中获得74.8分的突破性表现,超越了先进的对手Claude Opus 4与DeepSeek V3.1,显示出极强的工具调用与任务执行能力。并且,Qwen3-Max的推理变体Qwen3-Max-Thinking令人瞩目。配备了代码解释器并结合并行测试时计算,该版本在AIME 25和HMMT等数学推理顶级竞赛中均取得满分成绩,展现了非凡的逻辑推理与复杂问题解决能力。目前,Thinking版本仍处于密集训练阶段,未来将为学术研究与实际应用带来更多惊喜。
从开发者角度来看,Qwen3-Max提供了与主流OpenAI API兼容的接口,方便全球开发者快速接入和部署。通过阿里云平台,用户只需注册账号、激活Model Studio服务并获取API密钥,便能轻松调用强大的Qwen3-Max模型进行对话、编程、文本生成等多种任务。这种开放生态极大降低了AI技术的使用门槛,推动了各行各业智能化转型的速度。Qwen3-Max的出现不仅体现了规模效应在AI模型中的重要地位,也标志着技术实现从单纯参数堆砌向精细结构优化的转变。强大的训练稳定性、多维度的性能提升以及丰富的应用场景让Qwen3-Max成为业界关注的焦点。未来,随着Thinking版本的发布以及持续优化,Qwen3-Max有望在知识推理、多模态交互、智能辅助决策等领域发挥更大作用。
总结来看,Qwen3-Max的研发成功完美验证了"Just Scale It"的理念。通过极致规模与创新机制的结合,Qwen团队不但突破了传统训练难题,更缔造了功能多元的人工智能新高度。它引领了大型语言模型的技术发展趋势,为自然语言处理和智能代理任务注入了强劲动力。期待Qwen3-Max及其后续版本为全球AI产业注入不竭活力,开启智能计算新时代的辉煌篇章。 。