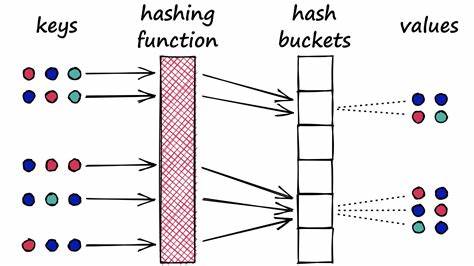
随着大数据和人工智能技术的高速发展,海量信息的高效处理需求日益提升,尤其是在相似性搜索和数据聚类领域。局部敏感哈希(Locality-Sensitive Hashing,简称LSH)作为一种独特的模糊哈希技术,因其能够将相似的输入数据映射到同一哈希桶中而备受关注。其核心理念在于通过牺牲传统哈希的低碰撞要求,最大化相似数据的碰撞概率,从而极大地优化高维数据的处理效率。本文将条理清晰地介绍LSH的基本定义、主要算法、性能优化与实际应用,帮助读者建立全面深刻的理解。 局部敏感哈希的概念源于度量空间和相似度函数。在数学意义上,设定一个度量空间以及相应的距离函数,LSH家族即指能够保证距离较近的点以较高概率映射到同一桶,距离较远的点以较低概率映射到同一桶的一类哈希函数集合。
具体表现为给定某个距离阈值r和放大因子c,满足距离不超过r的数据点以至少p1的概率哈希碰撞,而距离大于cr的数据点碰撞概率不超过p2,其中p1大于p2,这种敏感性的设计为后续近似算法奠定了性质基础。 除此之外,LSH也以相似度函数角度定义,构建一个哈希函数族,使得两个输入元素哈希碰撞的概率等于其相似度函数值。例如在集合的Jaccard相似度计算中,利用min-wise独立置换算法设计的哈希函数可精确满足该期望概率,极大简化了基于相似度的高效索引与查询。 局部敏感哈希的构建方法多种多样,针对不同的距离度量设计了相应方案。对于汉明距离的向量,最简单粗暴的方法是从输入位向量中随机抽取一位作为哈希函数,使得距离较近的向量在随机位相同的概率较高。另外,min-wise独立置换法则针对集合的Jaccard相似度,通过随机抽取置换映射集合最小元素实现哈希。
更复杂的方案包括基于随机超平面的SimHash,它针对余弦相似度利用随机超平面产生二元哈希值,概率分布与角度成比例。除此之外,利用稳定分布设计的哈希函数可适应Lp距离等度量,有效映射高维实向量空间中的相似度关系。 为了增强LSH的实用性及提升准确率,通常采用阈值放大技术,即AND构造和OR构造。AND构造通过将多个独立哈希函数的结果连接,降低远距离数据碰撞率,提高区分度,类似设立更严格的筛选门槛。OR构造则通过多个哈希函数间的并集扩展覆盖范围,保证近邻的召回率。灵活选择与结合这两类构造,成为实际系统设计时调整性能和效率的重要手段。
利用局部敏感哈希进行近似最近邻搜索体现了其最核心的价值。面对维度极高、数据海量的环境,传统精确算法因“维度灾难”而计算开销骤增甚至不可行。LSH通过预处理,将数据点分布到L个哈希表,通过查询多桶快速定位潜在近邻,实现时间上的显著节约。其时间复杂度和空间复杂度均可根据哈希函数数量k和哈希表数量L调节,系统参数的优化直接关系检索效果。其概率保证使得在满足一定近似比条件时,查询成功率可达到较高水平。 LSH的应用范围极为广泛,从文本近似去重、图像相似搜索、到基因组关联分析均有所涉及。
互联网领域,如搜索引擎优化、社交媒体内容推荐,均依赖于高效的相似数据识别。音频指纹识别和数字视频指纹技术借助LSH快速实现媒体内容的匹配检测。数据库管理系统中,利用局部敏感哈希进行物理数据组织,优化访问路径和存储布局,提升系统整体性能。而在机器学习训练过程中,LSH则能加速神经网络中大规模连接权重的稀疏更新,支持超大规模模型的高效训练。 近年来,针对LSH的性能瓶颈与实际需求纷纷提出优化改进方案,借助智能算法与硬件加速实现哈希计算的时间压缩。同时,数据感知的哈希函数设计如k-means哈希,在充分利用数据分布结构优势的同时保证理论性能,显示出更强适应性和效果。
此外,语义哈希借助深度神经网络模型将高维数据映射到紧凑语义空间,有效克服传统哈希在复杂语义捕捉上的不足,推动了机器理解能力的发展。 开源社区也积极贡献多种成熟的LSH实现,如Nilsimsa哈希针对邮件相似性设计,TLSH哈希聚焦数字取证与安全领域,均以不同侧重点演示了LSH技术的灵活性和实用性。用户可依托现有良好文档和代码,快速集成到各类应用场景,缩短研发周期。 总结来看,局部敏感哈希作为解决大规模高维数据近似检索的核心技术之一,凭借其概率驱动的哈希机制,成功突破传统方法的计算瓶颈,广泛适用于多领域多数据类型。其理论基础坚实,演化路径丰富,技术要点清晰,成为数据科学工程师和研究人员不可或缺的工具。未来,随着数据规模持续爆发和算法创新推进,预计LSH将在实时数据分析、个性化推荐、智能安全等领域发挥更大潜能,持续引领大数据时代的相似性搜索革命。
。