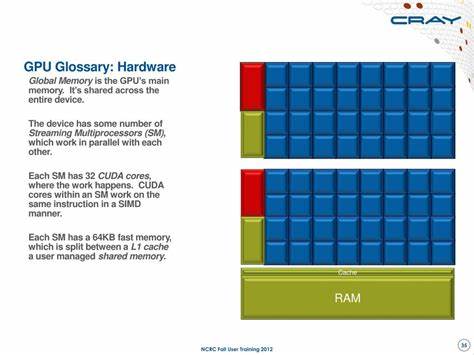
图形处理单元(GPU)作为现代计算领域不可或缺的重要硬件部件,已远远超越了传统的图形渲染功能,成为人工智能、深度学习、高性能计算以及游戏开发等多个领域的核心动力。深入理解GPU相关的专业术语和架构,有助于专业人士和技术爱好者更好地掌握其工作原理及性能优化方法,提升实战工程能力和研究水平。本文将围绕GPU的硬件结构、软件平台与性能指标展开系统讲解,打造一份详尽而实用的GPU术语指南。 GPU的硬件架构是理解其工作机制的基础。最重要的组成部分是CUDA架构(Compute Unified Device Architecture),它是一种并行计算架构,设计为充分利用GPU的计算资源。CUDA架构中的基本计算单元是Streaming Multiprocessor(流多处理器,简称SM),SM内包含多个CUDA核心。
每个CUDA核心承担浮点运算的任务,与传统CPU中的核心类似,但因设计针对高并行度计算场景而差异显著。SM除了CUDA核心之外,还配备Special Function Unit(特殊功能单元,SFU),负责执行复杂数学函数如三角函数和指数运算。Load/Store Unit(加载/存储单元,LSU)负责数据的读写操作,确保计算单元能及时获取和存储数据。调度器(Warp Scheduler)在SM内部负责组织和安排线程的执行,以最大化硬件利用率。 线程是GPU编程的基本执行单元,多个线程组成Warp(通常为32个线程),Warp是GPU调度和执行的最小单位。Warp Scheduler确保Warp中的线程同时执行指令,实现高效的SIMD(单指令多数据)并行处理。
为了更高效地管理大量线程,CUDA提出了Hierarchical Thread Organization(线程层次结构),包括Thread(线程)、Thread Block(线程块)以及Grid(网格)三个层级。在实际编程中,将计算任务划分成线程块,线程块集中组成线程网格,能够极大提升并行计算效率。 线程在计算中访问各种级别的内存,CUDA定义了复杂的Memory Hierarchy(内存层次结构)以优化性能。Register(寄存器)为每个线程提供最快的访问速度,是存储局部变量的主要区域。Shared Memory(共享内存)被同一线程块内的所有线程共享,延迟低且带宽高,适合线程间频繁交换数据。Global Memory(全局内存)容量大但延迟较高,供整个GPU所有线程访问。
高效的内存访问策略如Memory Coalescing(内存合并)和避免Bank Conflict(银行冲突)对于提升GPU性能至关重要。 CUDA不仅仅是硬件架构,还是一个完整的软件平台。CUDA C++作为主要编程语言,使开发者能以类似C++的语法编写针对GPU加速的程序。为支持这一平台,NVIDIA提供了丰富的软件工具和驱动,包括nvidia.ko内核模块、CUDA Driver API(libcuda.so库)以及CUDA Runtime API(libcudart.so库),这些组件协同工作简化了开发和部署流程。结合NVIDIA Management Library(NVML,libnvml.so)和nvidia-smi命令行工具,可以方便地管理GPU设备状态和资源使用。 在GPU开发中,性能分析与优化是关键环节。
理解Performance Bottleneck(性能瓶颈)的类型有助于针对性改进。Roofline Model是一种直观的性能分析工具,帮助识别当前计算是受Compute-bound(计算受限)还是Memory-bound(内存受限)影响。Arithmetic Intensity(算术强度)表示每字节内存访问所执行的计算量,是衡量程序效率的重要指标。GPU执行过程中不可忽视的因素还包括Occupancy(硬件占用率)和Warp Divergence(Warp分歧)。高占用率表明SM资源被充分利用,而Warp分歧则可能引发性能下降,因为同一个Warp内不同线程执行不同分支时,会导致串行执行。为了提升效率,还需关注Branch Efficiency(分支效率)、Latency Hiding(延迟隐藏)与Register Pressure(寄存器压力)等细节。
NVIDIA提供丰富的编译和性能分析工具支持GPU应用开发。nvcc是官方CUDA编译器驱动,支持将CUDA源代码编译为可执行程序或GPU二进制文件。CUDA Profiling Tools Interface(CUPTI)与NVIDIA Nsight Systems为用户提供了强大的性能剖析和调试能力,帮助定位性能瓶颈,调整资源分配。为特定工作负载设计的库如cuBLAS(CUDA基础线性代数库)与cuDNN(深度神经网络库)则大幅简化了高性能计算和AI模型开发。 从整体架构层面看,GPU不仅包含多个SM,还集成了Texture Processing Cluster(TPC,纹理处理集群)和Graphics/GPU Processing Cluster(GPC,图形处理集群)。TPC专门用于处理纹理映射和相关操作,而GPC则协调多个TPC,完成复杂的图形渲染和通用计算任务。
其中Register File、L1 Data Cache和Tensor Memory作为关键存储结构,保证了高带宽、高效的数据流动。Tensor Memory Accelerator(TMA)引入后更优化了张量数据的加载与存储,支持AI训练和推理中的张量操作。 为了有效使用GPU资源,理解Warp Execution State(Warp执行状态)、Active Cycle(活跃周期)和Pipe Utilization(流水线利用率)非常重要。Warp Execution State反映了每个Warp的当前执行进度,判断激活和挂起状态。Active Cycle是指SM中活跃指令阶段的比例,是衡量吞吐量的指标。流水线利用率则体现了计算单元与内存通道的配合效率。
高效的Issue Efficiency(指令发射效率)和Streaming Multiprocessor Utilization(SM利用率)直接影响到整体性能。总而言之,通过深刻认识GPU的硬件构成、编程模型和性能优化策略,开发者能够发挥其极致算力,为复杂的计算任务提供强力支持。掌握GPU专业术语不仅有助于技术交流,更是构建高性能GPU应用的基石。未来,随着计算需求的增长与技术的不断创新,GPU将继续在边缘计算、大数据分析及智能制造等领域扮演关键角色。理解其内部结构与工作原理,将成为推动科技进步不可忽视的重要力量。 。