随着人工智能、科学计算、大数据分析等领域对计算能力的需求不断提升,GPU编程的重要性日益凸显。CUDA作为NVIDIA专为GPU设计的并行计算平台和编程模型,凭借其强大的性能优势,成为众多开发者加速应用的首选工具。然而,要真正掌握CUDA编程,深入理解并灵活运用示例代码显得尤为关键。本文将全面解析一个开源CUDA示例代码库的结构和内容,帮助开发者系统掌握CUDA编程精髓,并提高实际项目中的开发效率。 该CUDA示例代码库由经验丰富的开发者维护,旨在为CUDA C++开发者提供实用的代码示范和学习资源。库中的设计理念着眼于实战应用,以多个主题模块划分示例类型,涵盖从CUDA程序初始化、内存管理、核心计算内核实现,到性能优化和程序性能分析等多个方面,满足不同层次开发者的学习需求。
代码库分为多个主目录,其中SetupAndInitExamples模块专注于CUDA程序启动初期的环境设置和初始化流程,帮助开发者了解CUDA环境的配置、设备检测,流和事件的创建等基础操作。此部分内容适合刚接触CUDA的开发者,能够协助构建坚实的基础知识体系。 MemoryAndStructureExamples模块围绕CUDA内存管理和数据结构展开。该模块不仅介绍了设备内存和主机内存的分配、释放机制与数据传输,还涵盖了怎样高效组织代码和数据以利于GPU内核的高效计算。实际案例演示了共享内存、常量内存、纹理内存的应用场景及性能对比,帮助开发者增强对内存层次结构的理解。 KernelAndLibExamples板块则重点呈现如何编写CUDA内核函数,以及CUDA内置库如Thrust的使用方法。
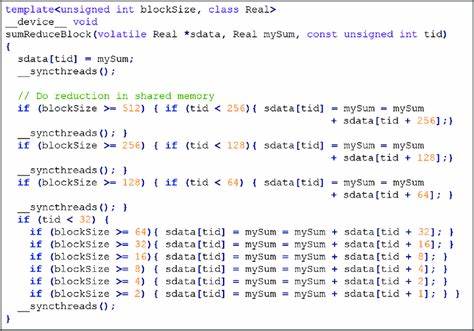
该部分展示了典型的向量加法、矩阵乘法等常见计算,辅以库函数的调用示例,具体展示如何组合内核与库函数以满足复杂计算需求。 ProfilingExamples包含如何使用CUDA自带的工具和命令对程序进行性能分析的示范。通过示例代码,开发者可以掌握使用NVIDIA Nsight、nvprof等工具定位性能瓶颈,分析内核执行时间、内存带宽利用率、线程发散等关键指标,从而针对性地优化CUDA程序。 PerformanceChecklist部分基于NVIDIA官方的性能优化清单,结合实践经验,展示了性能提升的策略和注意事项。示例代码讲解如何通过调整线程块大小、减少内存访问延迟、优化指令发射顺序等方式,显著提升计算效率。 此外,TensorParallelFromScratch作为进阶内容,深入探讨了基于CUDA实现张量并行计算的方法。
该模块结合作者的博客系列,完整展现了从零实现张量分布式计算的流程,适合希望掌握分布式深度学习加速技术的开发者。 代码仓库还强调规范与贡献准则,为社区持续发展奠定良好基础。每个示例都放置在独立的子目录中,确保结构清晰。所有执行程序均命名为main,便于统一管理和忽略无意义文件。示例代码兼容C++20标准,并且通过统一的错误检查宏包装CUDA API调用,保证了安全性与代码整洁。 项目采用CMake构建系统,默认支持架构版本86,支持多架构编译选项,极大方便了不同硬件环境下的编译与部署。
尽管Makefile相对简单,开发者可根据需要自行调整或提交补丁以完善。 通过实战示例,开发者能够系统掌握CUDA编程流程,从程序初始化、内存管理、内核设计,到性能分析与优化,建立完整的技能体系。该示例库不仅适合CUDA新手入门,更对有一定基础的开发者提供丰富的进阶资源和参考范例,有力支撑开发者提升代码质量与性能。 在实际应用层面,CUDA示例代码展示的技巧对于深度学习模型训练、图像处理、科学计算等领域具有重要参考价值。掌握示例中的设计模式和优化策略,有助于加速创新并有效利用GPU计算资源。 总体来看,该CUDA示例代码库以模块化、规范化的方式呈现,操作易上手且覆盖广泛,成为学习和应用CUDA的宝贵资源。
无论是CUDA新手还是资深开发者,都能在这里找到提升技能与解决问题的灵感。随着GPU计算需求的不断增长,持续探索与深耕CUDA编程,已成为推动科技进步和应用突破的重要驱动力。