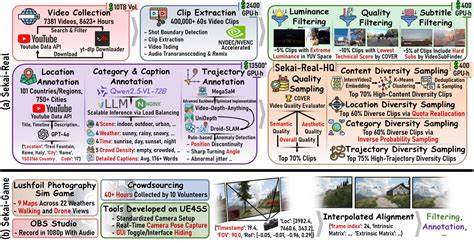
随着人工智能和计算机视觉技术的飞速发展,视频生成和虚拟世界探索成为研究重点。传统的视频数据集大多存在地点受限、场景静态、时长短暂等诸多不足,难以满足未来交互式、多场景的世界探索需求。为此,Sekai数据集作为一个开创性的全球第一人称视角视频资源库应运而生,旨在为探索式视频生成和互动体验提供坚实基础。Sekai,源自日语中“世界”的含义,向人们呈现了超过5000小时丰富多样的行走和无人机视角视频,覆盖全球100多个国家及750座城市。数据集充分体现了多样化地理环境和文化场景,为世界探索提供了真实、动态和全面的视角。构建Sekai数据集的团队通过先进的采集工具和注释系统,对视频中的位置、场景类型、天气状况、人群密度、视频配文以及摄影机轨迹等进行了详细标注,极大地提升了数据质量和应用价值。
这样的多维度注释不仅便于研究人员实现精确检索和情景模拟,还为训练深度学习模型提供了更加丰富的信息载体。Sekai的数据来源涵盖第一视角(FPV)和无人机视角(UVA)两种拍摄模式,兼顾了贴近人类视角的沉浸感和宏观俯瞰的全局视域。这一设计使得视频生成模型在模拟真实世界的动感和复杂性时表现更加出色。基于Sekai数据集,研究团队开发了交互式视频世界探索模型YUME,日语中意为“梦想”,不仅能够生成真实感极强的视频内容,还支持用户与虚拟环境进行动态互动,开启了视频生成技术在虚拟旅游、智能导航、教育训练等领域的广阔应用前景。数据集质量经过多项实验验证,展现出了出色的多样性、连续性和注释精准度,深受计算机视觉社区的认可。Sekai的问世不仅促进了视频生成技术的发展,也为人工智能在地理位置理解、视频内容生成和场景交互等方向提供了宝贵资源,极大地推动了虚拟世界探索的技术革新。
这种高度集成的全球视频数据集使得模型能够更好地理解地域差异、环境影响以及动态场景变换,从而在智能机器人导航、虚拟现实场景构建和自动驾驶等技术中发挥重要作用。面对庞大且复杂的世界探索需求,Sekai提供了一个覆盖面广泛而细节丰富的资源库,为研究者和开发者提供了强大的数据支持。未来,结合Sekai数据集的发展和优化,视频生成和交互技术有望实现更高水平的智能化,使人类能够以全新视角探索世界,跨越物理边界,感受全球丰富多彩的文化和自然风貌。此外,Sekai还鼓励开源共创精神,项目团队开放了相关工具箱,使研究人员能够更高效地收集、预处理和标注视频数据,促进社区协作与资源共享。作为一项具有里程碑意义的工作,Sekai不仅为学术研究提供了有力支撑,也为产业界激发了创新活力。无论是虚拟旅游、城市规划还是智能监控,Sekai都为这些应用场景提供了强有力的数据基础,为构建智慧城市和智能生活奠定了基础。
总之,Sekai数据集代表了视频生成和世界探索领域的一次重大突破,将推动相关领域迎来技术新高峰。它为学术界与工业界的合作创造了桥梁,开启了更加智能、高效和多样化的视频交互新时代。从多样化的视频内容到细致入微的注释,Sekai的设计理念体现了对世界的深刻理解和对技术未来的无限期待,彰显了全球信息共享和合作创新的力量。