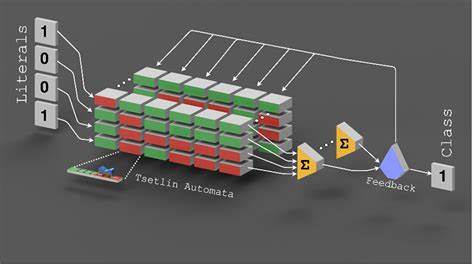
随着人工智能与机器学习的发展,算法的优化与创新成为推动技术进步的关键因素。Tsetlin机作为一种基于逻辑推理的新型机器学习算法,以其独特的布尔逻辑机制和高效的硬件实现优势引起了科研界和工业界的广泛关注。然而,传统Tsetlin机的"全或无"条款评估策略限制了模型的灵活性和效率,导致在处理复杂数据时需要庞大的条款数,增加了计算负担和资源消耗。近年来,模糊模式Tsetlin机(Fuzzy-Pattern Tsetlin Machine,简称FPTM)应运而生,凭借其模糊评估机制为Tsetlin机家族带来了革命性突破。模糊模式Tsetlin机的最大创新在于将传统的严格布尔逻辑转换为模糊逻辑条款评估。在标准模型中,只要某一个条款中的字面特征未满足,整个条款即被视为失效,无法对最终决策进行投票。
这种"全有全无"的逻辑导致需要数以千计的条款才能保证模型表现出色。相比之下,FPTM引入模糊评估机制,允许条款中的部分字面特征未满足时,剩余特征仍然能够以一定的权重贡献于整体决策。这意味着每个条款被视为多个子模式的集合,这些子模式可以根据输入数据进行更具弹性和适应性的组合,从而实现高效、鲁棒的模式匹配。由于模糊机制的引入,FPTM在多项主流数据集上表现出了卓越的性能优势。在IMDb影评数据集上,FPTM仅使用每类别一个条款便达到90.15%的准确率,其条款数量和所需内存较传统的Coalesced Tsetlin Machine减少了50倍,训练速度也快了数百倍,训练时间从数小时缩短至不到一分钟。这种大幅度的提升使得FPTM非常适合嵌入式设备甚至微控制器上的在线学习,实现真正的边缘智能。
对于视觉领域的经典测试集Fashion-MNIST,FPTM通过少量条款即可达到90%以上的准确率,且随着条款数量的增加模型精度持续提升,远远优于传统方法所需的庞大条款数量。更重要的是,FPTM在面对含有噪声的亚马逊销售数据集时依然表现出色,以85.22%的分类准确率显著超过了图形Tsetlin机和图卷积神经网络,体现了其在实际复杂环境下的强大鲁棒性。FPTM的高性能不仅来自模糊评估这一核心创新,还伴随着新的超参数设计,尤其是引入了"LF"参数,该参数限定了条款中允许忽略的字面特征数目,灵活控制了模型的容错程度。该设计极大地提升了训练的稳定性和泛化能力,并简化了模型参数调优过程。在实现层面,FPTM基于Julia语言开发,充分利用多核CPU的并行计算能力,实现了高效的训练与推理过程。多种开源示例覆盖了文本分类、图像识别及时间序列分析等多个领域,方便研究者和开发者快速入门及二次开发,推动了模糊逻辑机器学习算法的推广与普及。
未来,模糊模式Tsetlin机有望在物联网、智能诊断、实时决策系统等对计算资源有限且需要高精度模型的应用场景发挥巨大潜力。其轻量级架构和强大的泛化能力将助力实现更多边缘计算设备上的人工智能部署,赋予机器学习模型更强的自适应性和容错能力。总而言之,模糊模式Tsetlin机以其开创性的模糊评估策略打破了传统机器学习"硬"逻辑的桎梏,不仅显著优化了模型效率和准确率,更为未来的智能应用提供了新的技术方向。随着算法的不断完善与应用领域的不断扩大,FPTM有望成为引领智能计算新时代的重要引擎,推动人工智能技术迈向更高阶、更广泛的应用舞台。 。









