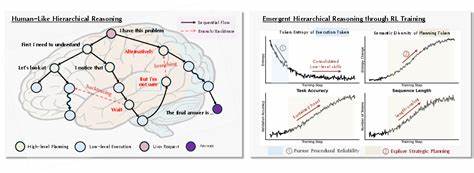
近年来,大语言模型(LLMs)在自然语言处理领域取得了显著进展,为文本生成、问答系统、机器翻译等多项应用提供了强大支持。然而,面对复杂推理任务时,如何有效提升模型的思考深度与决策质量,仍然是业内关注的焦点。强化学习(Reinforcement Learning,简称RL)作为一种优化方法,因其能在动态环境中进行连续决策而备受青睐。最新研究表明,强化学习不仅助力大语言模型提升性能,更促进了模型内部层级推理机制的自然涌现,为理解和优化智能推理提供了新视角。对于大语言模型来说,推理并非单一维度的"线性思考",而是类似于人类认知中的"多层次策略制定"。研究者发现,模型通过强化学习经历了从底层程序执行到顶层战略规划的双阶段学习过程。
最初阶段,模型专注于提升低级程序正确性,也就是确保每一步操作的准确性和合理性。随着低级技能达到一定水平,瓶颈转移至高层策略优化,即如何在整体上做出有效规划以实现长远目标。这种分层现象被形象地比拟为人类决策中"高层战略规划"与"底层执行步骤"的分离,彰显了机器学习中复杂认知框架的内在逻辑。然而,传统强化学习算法在优化大语言模型时面临一大挑战:优化压力被平均分散至所有预测的词元(token),导致学习信号被稀释,尤其低效于高影响力的关键推理步骤。这种泛化优化策略限制了模型在高层次思考方面的快速突破。针对这一问题,研究团队提出了一种名为"层级感知信用分配"(Hierarchy-Aware Credit Assignment,HICRA)的创新算法。
HICRA通过聚焦于对整体推理结果影响最大的"规划词元",将优化资源更精准地导向高层策略的学习,极大提升了模型在复杂推理任务上的表现和样本效率。实验结果显示,无论是在推理准确率还是推理速度方面,采用HICRA算法优化的模型均显著优于现有主流基线,为推动大语言模型智能化发展提供了强有力的工具支持。研究中还观察到诸多有趣现象,如"灵光一现"的突破时刻(aha moments)、推理复杂度随问题长度增长呈正相关的"长度-规模效应"以及熵值动态变化规律。这些都印证了推理层级的动态演进,即从程序正确性向战略探索转移的过程。此发现不仅深化了对强化学习中内部认知机制的理解,也揭示了未来设计更高效、更智能的语言模型优化策略的潜在方向。层级推理的自然涌现为AI系统的设计理念带来启示。
传统上,人工智能系统往往在设计时将计划与执行分为明确模块,而此次研究展示了通过强化学习,模型内部能够自发形成类似的人类认知层级,减少人工干预,增强自适应能力。这为构建更加灵活且具备解释能力的智能系统奠定了基础。业界和学术界对这一发现表现出极大兴趣,认为它为实现真正具备"战略思考"能力的AI迈出了关键一步。未来,结合层级推理机制优化的大语言模型,有望在复杂任务如科学发现、法律分析、策略游戏等领域展现卓越表现。同时,该机制在多模态学习、跨领域知识迁移等方面亦蕴含广泛应用潜力。总而言之,通过强化学习实现的层级推理涌现,正在推动大语言模型向更高认知水平迈进。
HICRA算法的提出不仅解决了传统强化学习中的优化瓶颈,更揭示了人工智能在认知结构上的新路径。随着技术不断成熟,层级推理有望成为未来智能系统设计的核心范式,促进AI技术在日常生活和专业领域的深度融合和广泛应用。继续深入研究这一领域,将加速智能机器理解和执行复杂任务的能力,开创AI发展的新纪元。 。