蛋白质的功能高度依赖于翻译后修饰(post-translational modifications, PTMs),包括磷酸化、泛素化、乙酰化、甲基化、糖基化等。准确识别和验证这些修饰位点通常需要用定点突变策略来干预修饰的发生或模拟修饰的状态。掌握氨基酸突变的基本规则和实验设计原则,是进行蛋白功能机制研究的关键。下面从常见修饰类型出发,系统总结突变设计原则、实验实现与常见陷阱,便于科研工作者在课题研究中快速选择合适的策略并提高结论可靠性。 磷酸化常见发生在丝氨酸(Ser, S)、苏氨酸(Thr, T)和酪氨酸(Tyr, Y)残基。制备功能失活型突变体的常见做法是将S或T替换为丙氨酸(Ala, A),把Y替换为苯丙氨酸(Phe, F)。
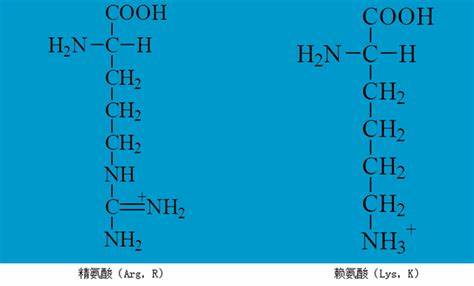
这些替换通过去除可被磷酸化的侧链羟基来阻断磷酸化,同时保留一定的体积和疏水性以减少对整体构象的影响。为产生磷酸化模拟的"激活"突变,可以将S、T或Y替为酸性氨基酸如谷氨酸(Glu, E)或天冬氨酸(Asp, D)。需要强调的是,酸性残基只能部分模拟磷酸化带来的负电荷,不能复制磷酸基的结构体积、空间构象或可被磷酸特异性识别的氢键网络。因此对于关键位点,磷酸模拟突变的表型应结合磷酸化特异性抗体、质谱等直接证据共同判断。 泛素化、乙酰化和其他酰化修饰多发生在赖氨酸(Lys, K)残基。研究者常用的阻断策略是将K替换为精氨酸(Arg, R),理由是R与K同为碱性侧链、带正电,能在一定程度上维持局部电荷分布与构象,同时去除赖氨酸的ε-氨基以阻止泛素或酰基的偶联。
对于泛素化链类型分析,常用的方法是构建位点特异性的泛素表达载体。比如要研究K48链相关的功能,在泛素序列中把除K48外的所有赖氨酸都突变为R,从而使表达的泛素只能在K48位形成链。相应地可以构建K63、K11等"位点专一"泛素载体,帮助解析不同多泛素链的生物学后果。在体内或体外过表达体系中,可同时转入标签化的泛素、泛素连接酶或E3以及靶蛋白,配合免疫沉淀(IP)和免疫印迹(Western blot)来确认泛素化修饰及链类型。进行泛素化检测时应注意使用变性条件的IP以减少非共价相互作用带来的干扰,并用去泛素酶抑制剂(如NEM)保护修饰信号。 甲基化可以发生在赖氨酸和精氨酸上,但两者的甲基化形式与生物学含义不同。
赖氨酸可形成单甲基、二甲基或三甲基,而精氨酸可形成单甲基、对称二甲基或非对称二甲基。针对赖氨酸甲基化的功能失活策略通常将K替换为R来阻断甲基化,但要注意K→R替换可能引入新的相互作用或不同的酶识别特性。对于精氨酸甲基化,常见的替换是将R替为赖氨酸(K)或丙氨酸(A),其中R→K可改变侧链的化学可修饰性(R甲基化改为K可能导致新的乙酰化或甲基化可能性),R→A作为更彻底的非保守替换更能阻断甲基化,但同时可能破坏结构或结合界面。设计甲基化相关突变时,必须考虑残基在蛋白相互作用界面或结构核心的定位,必要时通过蛋白结构或同源建模评估替换对整体构象的影响。 糖基化包括N-糖基化和O-糖基化两类常见类型。N-糖基化典型发生在Asn-X-Ser/Thr的保守基序中,其中X可以是任意氨基酸但不能是脯氨酸。
阻断N-糖基化的常用方法是将天冬酰胺(Asn, N)替换为谷氨酰胺(Gln, Q),因为Q保留了侧链的極性和相似体积但不能形成N-糖键,从而在较小程度上保持局部折叠。对于O-糖基化,常将可被糖基化的丝氨酸或苏氨酸替换为丙氨酸(Ala, A)以去除羟基供体。需注意的是糖基化对蛋白稳定性、折叠和细胞定位可能影响显著,因此在解释突变表型时应结合表达量、分泌效率或膜定位等数据。 在具体突变设计时,判断替换是否保守或非保守非常重要。保守替换通常保持相似的体积、极性或电荷,例如Lys↔Arg、Ser↔Thr、Asp↔Glu,可以在尽量不破坏蛋白整体构象的前提下改变可修饰性。非保守替换如Ser→Ala、Tyr→Phe或Lys→Ala更可能造成局部结构或功能变化,但有时正是需要通过"功能失活型"突变明确修饰的作用。
命名与记录突变时应采用标准格式,例如S312A表示第312位Ser突变为Ala,便于文献检索和实验记录。 针对多重修饰或修饰簇,单点突变可能不足以揭示生物学功能。有时需要构建多位点突变体,同时将多个潜在修饰位点一并阻断,或者逐步恢复某个位点来定位关键残基。多点突变的构建可通过分段克隆、叠加突变或合成基因实现。进行多点替换时应注意比较每个突变体的表达量和稳定性,以免误将表达差异解释为功能丧失。 在实验验证方面,结合多种方法可以显著提高结论的可信度。
经典方法包括突变体的细胞表达与功能测定、带标签的IP与Western blot检测修饰、质谱(MS)直接鉴定修饰位点、修饰特异性抗体检测以及功能性表型分析(如酶活性、蛋白降解、亚细胞定位或相互作用改变)。使用质谱是确认修饰位点的金标准,但需要合适的富集策略(如抗体富集、化学富集或亲和捕获)来提高灵敏度。对于泛素链类型判断,可以结合特异性链识别抗体或使用位点限制的泛素变体来间接证明链类型。 在解释突变结果时应谨慎。磷酸化模拟(S/T/Y→E/D)并不能完全等同于实际磷酸化,尤其在依赖磷酸基与识别蛋白直接相互作用的情况下可能失效。K→R替换虽然常用于阻断泛素化或乙酰化,但在某些情形下R侧链的氢键和空间占位不同,可能引入新的相互作用或稳定性变化。
R→K替换用于研究精氨酸甲基化的情形也需小心,因为赖氨酸同样是多种修饰的靶点。理想的验证路径是将突变结果与野生型的质谱证据、修饰特异性抗体检测以及功能性恢复实验相结合。 设计突变实验时还要考虑构建和表达系统。原位突变(基因组编辑如CRISPR/Cas9)能保留内源表达调控,避免过表达带来的假阳性,而过表达体系便于检测修饰但可能改变修饰酶动力学和位点选择性。实验对照应包括空载体、野生型蛋白、以及必要的非相关突变体。对突变体的稳定性、亚细胞定位和相互作用网络进行并行评估,有助于鉴别修饰直接功能与间接效应。
生物信息学工具在位点预测与突变设计中非常有用。磷酸化位点可以用NetPhos、GPS等软件预测,泛素化与乙酰化预测工具如UbPred、PhosphoSitePlus数据库提供了大量实验注释,糖基化预测可用NetNGlyc和NetOGlyc。预测结果应与进化保守性分析、结构信息以及实验数据结合,以提高候选位点的可信度。 最后,科研记录与可重复性不可忽视。详细记录突变构建策略、引物、克隆和测序结果,保留原始Western blot、质谱和功能实验数据,并在发表时提供足够的突变信息和实验条件,便于他人复现工作。学术交流中明确指出使用的突变类型(如功能失活型或模拟型)、构建方法和检测手段,有助于社区对相应结论的正确理解与延展。
理解和应用蛋白修饰位点的氨基酸突变规则,是解析信号传导、蛋白稳态和细胞功能调控的基础技能。合理选择替换类型、结合多重验证手段并考虑结构与生物学上下文,能够显著提高修饰研究的准确性与生物学价值。无论是研究单个关键位点,还是探索复杂的修饰网络,遵循上述原则都将帮助研究者更稳健地揭示修饰与功能之间的因果关系。 。









