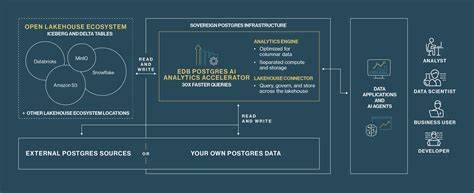
在大数据和实时分析需求日益增长的当下,数据库的性能瓶颈成为企业数字化转型过程中亟待解决的核心问题。EDB Postgres Distributed(简称PGD)作为企业级分布式Postgres数据库解决方案,通过其内置的分析加速引擎EDB Postgres Analytics Accelerator(PGAA),为用户带来了显著的查询性能提升,特别是在大规模数据分析场景中表现尤为突出。PGAA基于Apache DataFusion的矢量化查询引擎,能够实现与传统Postgres引擎的高效协同,极大地缩短复杂分析查询的执行时间。本文将深入解析PGD与PGAA的架构特性,展示如何构建高效的分布式分析环境,并通过实测数据说明其带来的性能优势。 EDB Postgres Distributed是EDB的旗舰产品之一,旨在提供企业级分布式数据库解决方案,支持多节点高可用和数据复制。其独特之处在于支持将生产数据无缝复制至分析格式 - - 基于Apache Iceberg的存储体系,从而实现分析数据与OLTP数据的解耦。
通过此机制,PGAA能够直接针对分析存储中的数据执行高效分析查询,避免传统Postgres查询过程中因事务处理和锁机制带来的性能开销。 搭建PGD集群并启用PGAA分析加速功能是体验其强大性能的第一步。通过注册EDB账号获取订阅令牌,用户可以方便地在Ubuntu 24.04环境下安装并配置PGD及相关组件。PGD的单节点示范环境通过CLI命令快速建立,完成后系统自动维护节点状态和数据同步,确保集群稳定运行。 PGAA的配置涉及调整postgresql.conf文件,开启特定参数以优化数据复制和刷新频率,并配置数据存储路径。PGAA通过创建Iceberg格式的存储位置,支持将数据写入本地文件系统或兼容的对象存储服务(如MinIO或S3)。
通过安装pgaa扩展,数据库实现对分析数据的高效访问,并在Postgres内部构建专用分析表,支持基于PGAA表访问方法的查询执行。 以一个存储客户订单数据的示例表orders为例,用户可以在PGD中生成大规模模拟数据,规模达到1亿行,模拟实际业务环境的高负载分析需求。设置完成后,PGAA会自动将数据同步并转换为分析格式,用户可通过创建以PGAA为表访问方法的orders_analytics表对数据进行分析查询。 实际查询测试中,使用hyperfine工具多次执行分别针对PGAA表和原生Postgres表的等价统计查询,结果显示基于PGAA的查询平均执行时间约为863毫秒,而传统Postgres引擎执行相同查询则需要约6秒时间。性能对比显示,分析引擎提升了近7倍的查询速度。这一显著差距主要源于PGAA采用了矢量化执行引擎,能够更好地利用现代CPU架构,实现高效的数据扫描和计算处理。
这种性能优势对于需要每天处理海量数据的企业尤为关键。提升查询速度不仅加快了分析决策的响应时间,也降低了计算资源消耗,减少了云环境成本。PGD与PGAA的结合使企业能够在保持Postgres生态兼容的同时,获得接近专用数据仓库的分析性能。 此外,EDB Postgres Distributed的分布式架构天生适合构建多节点集群,支持高并发和容错能力。虽然本文环境采用单节点配置简化演示,但实际生产环境中,通过多节点部署可以进一步提升系统的整体吞吐量和数据安全性。需要注意的是,在多节点环境下进行分析表的DDL操作时,可能会因为锁等待导致短暂阻塞,因此建议在复制同步稳定后再进行此类操作。
对于数据管理员和开发者而言,理解和掌握PGD及PGAA的部署细节是充分发挥其性能优势的基础。从设置环境变量、安装软件包、调整数据库配置参数,到创建复合表结构和运行分析查询,整个流程都经过优化设计,最大程度降低了操作复杂度,确保快速上手和高效输出。 未来随着PGAA功能的持续演进,用户预计无需再新建单独分析表,而是能够直接在既有Postgres表上激活分析引擎支持,实现无缝切换查询模式。同时,随着对多种存储后端支持的拓展,PGAA将进一步丰富底层数据访问能力,覆盖更多复杂分析场景。 总结来看,利用EDB Postgres Distributed和Analytics Accelerator增强数据查询性能,是企业实现数字化转型和智能分析的强力武器。通过数据复制至高效分析格式并结合Apache DataFusion矢量化引擎,PGAA实现了Postgres生态内分析效率的跃升,使数据驱动决策更加迅速精准。
这种兼顾开放性与高性能的架构方案,将为各行业处理大规模数据带来持久竞争优势。随着技术不断完善和应用场景拓展,预计EDB Postgres分布式分析引擎将成为数据库技术革新的重要推动力,引领新一代企业级数据库系统迈进智能高效的新纪元。 。