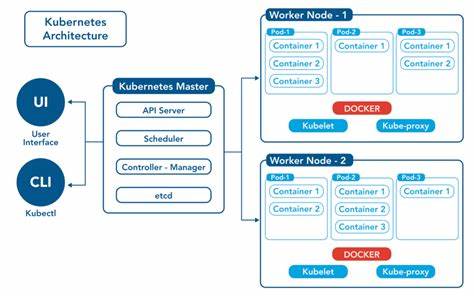
Kubernetes作为当下最受欢迎的容器编排平台,在云计算和微服务架构领域扮演着举足轻重的角色。它极大简化了应用的部署、扩展和管理,使得开发团队能专注于业务功能,而非底层基础设施的复杂配置。然而,与无状态应用资源不同,数据库作为有状态服务,在Kubernetes环境中始终存在着诸多管理难题,这些问题严重制约了Kubernetes在生产环境中的广泛应用。长期以来,数据库管理在Kubernetes中被视为一块“顽疾”,其复杂性主要源自于数据库的持久化数据和状态演进特性。传统的Kubernetes控制模型基于声明式配置和自动调节循环(reconciliation loop),非常适合快速替换和无状态资源的生命周期管理,但面对需要持续保存数据且不可随意替换的数据库实例,这种模型显得力不从心。更新数据库版本或执行模式迁移等操作,若按普通的Pod替换方式,往往伴随停机风险和数据损坏隐患。
尤其是在复杂的升级和架构演进过程中,如何确保数据一致性和业务连续性成为关键挑战。与此同时,数据库模式变更(Schema Migration)也是一个难点。应用程序开发迭代频繁,数据模型需要不断调整以满足新功能需求,一旦迁移计划执行不当,极易导致数据丢失、访问错误甚至系统崩溃。传统做法依靠脚本或初始化容器执行迁移命令,这些过程缺乏动态调整和容错能力,操作繁琐且难以集成进自动化流程。针对这些痛点,Kubernetes社区近年来提出了Operator模式,成为解决数据库管理难题的核心突破。Operator本质上是定制化控制器,扩展了Kubernetes的能力,使其能够管理复杂且领域特定的有状态资源,包括数据库集群、消息中间件等。
通过定义自定义资源(CRD),用户可以声明数据库集群、节点或数据库模式的理想状态。对应的控制器则持续监测当前状态与理想状态的差异,并根据预设逻辑执行有针对性的操作,实现自动化的状态修正。Operator不仅化繁为简,更赋予了集群“智能”,可以感知数据库当前运行状态,执行安全升级、故障恢复、备份恢复等任务。以PostgreSQL数据库为例,CloudNativePG Operator就提供了高可用、多副本、无缝升级等能力,极大降低运维难度和风险。而在数据库模式管理方面,Ariga的Atlas Operator进一步补充了声明式架构演进的理念。通过AtlasSchema自定义资源,开发人员能够以GitOps方式管理数据库模式,操作完全声明式,无需编写复杂迁移脚本。
Atlas Operator会自动检测模式变更的差异,智能生成合适的迁移计划并执行,实时反馈迁移状态,确保安全无缝地演进数据结构。这种模式打破了传统依赖手动和脚本的非声明式执行方式,将数据库管理真正融入Kubernetes的自动化生态系统,从而实现端到端的云原生数据库生命周期管理。对于企业和开发团队而言,这种变革极具价值。首先,它提升了数据库服务的可靠性和可用性。自动故障检测与恢复机制可减轻人工干预压力,避免因人为失误导致的停机。其次,升级和扩容操作变得平滑且无缝,支持零停机维护,业务连续性得到了保障。
此外,声明式管理方式有利于审计与合规,所有变更记录清晰明了,更适合敏捷开发和持续交付。借助Operator,团队可以将数据库基础设施视作代码(Infrastructure as Code),整个数据库环境的配置、扩展、升级、数据迁移流程都在版本控制的仓库中管理,实现真正的GitOps实践。与此同时,云原生生态中的其他工具和服务亦在不断完善配合数据库管控的能力。例如,结合Kubernetes内置的Secret管理功能,可以安全地处理数据库连接凭证。Observability工具的发展则让数据库运行状态和性能指标更易监控,方便快速定位问题。通过与CI/CD流水线深度集成,数据库变更的测试和审批流程也变得更加高效与安全。
可以预见,未来Kubernetes将在数据库管理领域发挥更大能量,成为支撑大规模云原生应用不可或缺的中枢。随着Operator模式和相关工具的成熟,甚至更多种类的数据库和有状态系统将被纳入Kubernetes统一管理之下。开发者和运维人员也将享受从手工操作向自动化、声明式治理的根本转变,实现效率与稳定性的双赢。总结来看,Kubernetes解决了长期以来困扰的有状态数据库管理难题,关键依赖Operator模式及配套工具的兴起。通过对数据库生命周期的智能感知和自动化修复,数据库服务真正成为云原生基础设施的一部分,与应用和服务共同构建敏捷、高效、可扩展的现代数字化系统。面对日益复杂的技术环境和业务需求,拥抱这一趋势必将为企业提供更强大的竞争优势和持续创新的能力。
随着更多实践经验积累,社区与厂商也将不断推动Operator生态的完善,使Kubernetes及其数据库管理能力走向更加成熟与普及的未来。