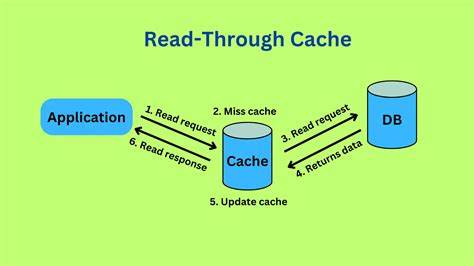
当今云存储的高速发展催生了庞大的对象存储需求,尤其是以Amazon S3为代表的分布式存储服务,成为了海量数据存储的主力军。然而,S3对象存储虽然具备高扩展性和极佳的持久性,但在面对频繁、随机访问大量数据的场景时,却难免遭遇延迟高、带宽受限等瓶颈。为了提升用户访问效率,业内开始越来越多地关注read-through缓存方案。Cachey正是在此背景下诞生的一个创新项目,针对S3对象存储带来了切实高效的缓存优化方案。Cachey是基于Rust语言打造的高性能read-through缓存服务,它采用混合内存与磁盘缓存架构,专门针对不可变的二进制大对象进行缓存处理。不同于传统缓存,它使用固定大小的16MB页面作为最小缓存单位,这样做有效地将任意字节范围的访问转换为对应页面的对齐加载,极大简化了缓存管理逻辑并提高了访问效率。
Cachey内置了智能的多桶支持能力,允许用户为同一对象指定多个S3桶的优先访问顺序。面对缓存未命中的请求,它将尝试在多个桶之间进行冗余访问,以保障数据的高可用性与稳定性。此外,它还能够基于内部延迟和错误统计动态调整请求策略,确保访问性能的最优化。 Cachey提升性能的另一个关键特性是所谓的"hedged requests"(对冲请求)机制。针对那些偶发的高延迟存储响应,它能够基于设定的延迟分位值发起冗余请求,从而最大限度地缩短请求响应尾时延。此机制在云存储场景下尤为重要,有助于防止单一慢请求拖累整体服务体验。
此外,为了高效处理并发请求,Cachey能够将多个对同一页面的请求整合为一次实际的存储访问,减少重复流量,极大地提升了整体吞吐量。Cachey通过简单的HTTP API对外提供数据读取服务,允许通过GET或HEAD请求访问任意对象的指定字节区间。使用时,客户端只需在请求头中指定字节范围、可能的优先桶集合及请求参数覆盖,即可享受缓存带来的性能红利。响应中会包含标准的HTTP范围返回码(如206 Partial Content)及特定的缓存状态信息,便于客户端判断数据来源及缓存命中状况。运维层面,Cachey还支持完整的监控和统计接口。通过/metrics端点可以将详细的性能指标导入Prometheus或其他监控系统,帮助工程团队实时掌握缓存负载、命中率、延迟分布等关键数据,从而做出及时的容量调整与策略优化。
Cachey的设计目标十分明确,聚焦于提升对象存储的读取效率,适合在视频、归档备份、大数据分析等对海量只读对象访问频繁的场景下应用。其开源性质为企业用户提供了极大的灵活性,能够根据自身需求调整缓存策略、定制缓存容量及持久化路径。与传统的文件系统缓存或内容分发网络相比,Cachey专注于云端对象存储的细粒度读写优化,以适应云上微服务的高速发展需求。对于开发者而言,Cachey同样友好。由于它遵循标准HTTP协议,前端调用简单直接,无需复杂的SDK或专有客户端支持。同时,Cachey支持通过命令行工具快速部署和调试,Docker镜像的存在使得运行环境搭建变得轻松高效。
尽管Cachey目前主要针对不可变数据有效,限制了实时频繁写入或更新的使用场景,但正是这种设计为缓存一致性与稳定性提供了保障,使其在目标方向上拥有极致的表现。未来,随着对象存储需求的多样化,Cachey也可能扩展更多智能策略以支持更广泛的应用。总结来看,Cachey是一个结合了现代云计算需求和高效缓存设计理念的高性能缓存工具。它通过固定页面缓存、智能桶选择、对冲请求和并发请求合并等创新手段,显著提升了S3兼容对象存储的读取速度和资源利用率。对于企业开发者和运维团队来说,合理利用Cachey可极大地降低存储访问的延迟和带宽压力,提升整体应用的用户体验和运行效率。随着云原生架构的普及和数据规模的爆炸式增长,类似Cachey这样的针对性缓存方案无疑将在未来的分布式存储生态中扮演越来越重要的角色。
。









