随着人工智能技术的快速演进,多模态大模型成为新时代AI发展的重要方向。Qwen3-Omni作为阿里巴巴云Qwen团队倾力打造的旗舰级多模态基础模型,凭借其原生端到端设计和对文本、图像、音频及视频的全面理解能力,引起了业界广泛关注。它不仅具备强大的多语言支持,还能实现自然流畅的实时语音生成,为智能交互和内容生产带来了革命性突破。Qwen3-Omni集成了多模态信息处理与智能对话于一体,赋予了人机交互更多维度的可能性,满足了零售、电商、教育、娱乐、客服等多个领域的需求。作为目前领先的开源多模态模型之一,Qwen3-Omni展现出优异的性能和极高的适用性,成为推动AI与现实深度融合的重要力量。其核心优势首先体现在多模态原生支持上。
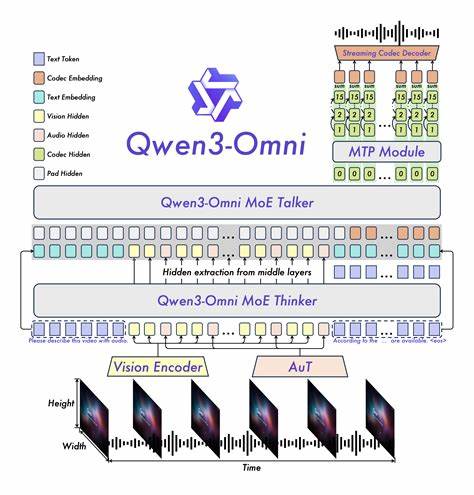
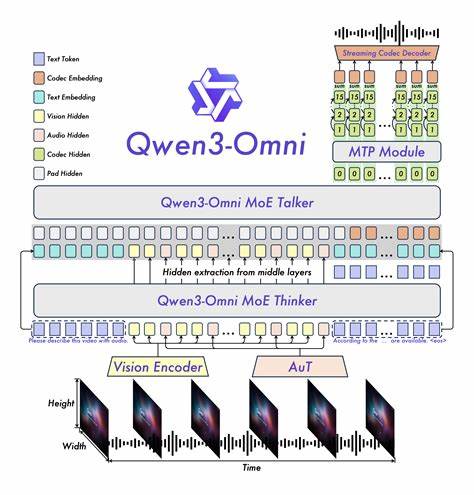
通过早期的文本优先预训练和混合多模态训练策略,Qwen3-Omni在保证单一模态最高性能的同时,实现了对跨模态信息的深度理解和协同推理。无论是文字、图片,乃至复杂的视频和音频输入,模型都能精准解析并产生合乎情境的输出,极大提升了智能交互的自然度和实用性。其次,Qwen3-Omni拥有广泛的多语言覆盖能力,支持119种文本语言、19种语音输入语言及10种语音输出语言。这一多语种特性不仅显著扩展了其应用地域和场景,还打破了语言障碍,让全球用户都能享受到智能化服务。尤其在国际化商务、多文化交流及跨境电商等领域,Qwen3-Omni有望发挥不可替代的桥梁作用。技术架构方面,Qwen3-Omni采用了创新的基于专家模型(MoE)的Thinker-Talker设计,并结合了AuT预训练阶段与多码本策略。
这种复合架构既保证了模型具备强大的泛化思维能力,也有效降低了推理延迟,实现了低时延的多模态实时交互体验。这对于语音助手、智能客服及实时内容生成等应用极为关键,提升了用户体验的流畅性和响应速度。值得关注的是,Qwen3-Omni在语音输入和输出的自然性方面表现突出,支持从中文、英文到韩语、阿拉伯语等多种语言的语音转写与生成,且性能媲美业内知名的专业语音模型Gemini 2.5 Pro。这体现了其多模态对话系统的先进水平,能够有效处理不同语种的语音交流,满足多样化国际用户的沟通需求。除了基础模型之外,Qwen3-Omni生态中还包含丰富的应用工具和示范用例,如细粒度音频描述模型Qwen3-Omni-30B-A3B-Captioner,它专注于低幻觉率、详细的音频字幕生成,填补了开源社区在多模态音频分析方面的空白。此外,模型配套的Cookbook教程涵盖语音识别、语音翻译、音乐风格分析、视频内容描述等多种场景,显著降低了开发门槛,让更多开发者和企业用户轻松开展创新实践。
基于性能评测,Qwen3-Omni在36项音频及音视频基准测试中,达成32项开源SOTA(状态最优),且在22项测试中超越包括Gemini 2.5 Pro与GPT-4o等闭源强劲竞争对手,展现出强劲的技术竞争力和行业领先地位。无论是在自动语音识别(ASR)、语音理解还是跨模态对话领域,Qwen3-Omni都实现了行业顶尖表现,为实际应用场景提供了坚实保障。为了满足不同用户的需求,Qwen3-Omni提供多种模型版本,包括Instruct版、Thinking版及Captioner版。Instruct版兼具Thinker和Talker,支持文本与语音的双向交互,更适合综合智能助理;Thinking版专注于深度推理和多模态理解,适合复杂分析场景;Captioner版则面向多样化音频内容生成详细字幕。这种灵活的模型设计,方便用户针对任务特点进行选择,大幅提升了应用的定制化和效率。在使用体验上,Qwen3-Omni同样表现出色。
支持Hugging Face Transformers、vLLM以及Docker多种推理环境,用户可选择适合的配置进行模型加载。vLLM作为高效推理引擎,特别推荐用于大规模部署和低延迟场景,结合FlashAttention 2技术,有效降低GPU内存消耗,提高推理速度。开箱即用的Docker镜像进一步简化了系统环境配置,助力企业快速落地。此外,阿里云提供的DashScope API支持离线及实时接口调用,方便开发者以云服务形式体验Qwen3-Omni功能,无需关心底层硬件部署,轻松实现多模态智能应用。在实际交互中,Qwen3-Omni能够实现视频音频同步理解,用户通过语音或文本提出问题,模型即时返回自然语音或简洁文字回复,适合智能家居、车载助手及在线客服等多样交互场景。配合精准的系统提示管理,模型能快速调整语气风格和角色身份,完善用户体验,兼顾专业性及亲和力。
展望未来,Qwen3-Omni在推动多模态AI普及方面具备巨大潜力。随着AI硬件的普及及性能升级,搭载Qwen3-Omni的智能设备将广泛落地,不仅提升人机交互的自然度,还能促进跨语言跨模态信息的高效沟通。其在教育辅导、医疗辅助、内容创作、智能安防等领域的应用前景更是令人期待。多模态+多语言的深度融合,将使信息获取和智能服务无界共融,打造更加智能和人性化的数字生活体验。总之,Qwen3-Omni以其前沿的多模态技术架构、卓越的多语言支持和灵活高效的推理能力,成为全球多模态智能领域的重要里程碑。它不仅推动了技术边界的突破,也为各行各业提供了强有力的智能赋能工具。
借助这款强大多模态基础模型,未来智能交互将更自然、更高效,真正实现人机之间无障碍的深度理解与协作,开启人工智能发展的崭新篇章。 。