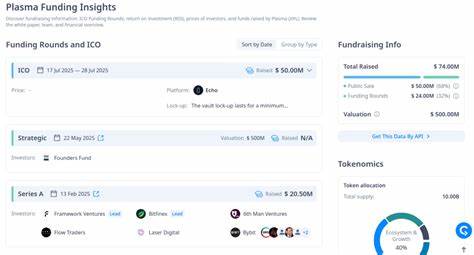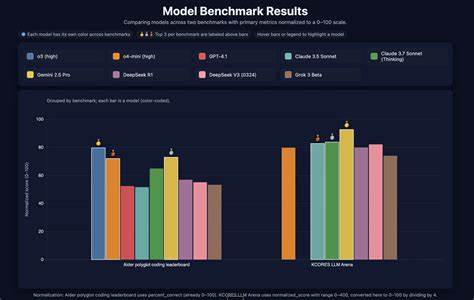
随着人工智能技术的不断发展,模型性能的评估变得尤为重要。尤其是在推理能力和诚实表现这两个领域,不同模型在各种测试基准上的表现往往存在较大差异。通过数据可视化手段直观地展示这些差异,可以帮助研究者和开发者更好地理解模型的优势和不足,从而优化其设计,提高应用的可靠性和有效性。 推理能力指的是模型在面对复杂问题时,能够进行逻辑判断、归纳总结和推断新结论的能力。这一能力对许多应用场景如智能问答、决策支持系统等具有重要意义。相对而言,诚实表现涉及模型在生成文本或决策时是否保持真实、准确和负责任。
这不仅关系到模型的可信度,也直接影响用户体验和社会伦理。 在实际评估过程中,研究人员通常会设计一系列专门的基准测试来衡量模型在推理和诚实方面的表现。这些测试涵盖了不同类型的问题和场景,譬如数学推理题、逻辑谜题、事实核查及道德判断等。通过定量评分,能够对比不同模型的优缺点,并揭示性能上的细微差异。 然而,单纯的表格或文字数据往往难以让人快速领会模型性能的全貌。此时,数据可视化成为关键工具。
将不同模型的得分通过二维或三维图表展示,能够清晰揭示它们在推理与诚实基准上的相互关系。例如,使用散点图分别以推理能力和诚实评分为横纵坐标,直观体现模型的整体表现分布。这种方式便于发现表现均衡或存在明显偏差的模型类型。 此外,通过颜色编码或气泡大小等视觉元素,可以加入更多维度的信息,如模型规模、训练数据量或推理速度。这样多层次的可视化为科研人员提供了丰富的数据洞察,帮助他们在权衡多种因素时做出更加合理的模型改进方案。 近年来,随着大型语言模型的兴起,对推理和诚实的需求日益增长。
许多顶尖模型如GPT系列、Claude等,都在持续优化其推理深度和回答的可靠性。利用标准化的基准测试结合数据可视化,可以有效跟踪各代模型的进步和瓶颈,为未来研究指明方向。 诚实表现的评估尤为复杂,因为它不仅涉及事实正确性,还牵涉模型避免生成误导性信息或偏见内容的能力。通过构建包含敏感话题和容易导致歧义的问题集,测试者能够更全面地审视模型的真实性。将这些测试结果以直观图形呈现,有助于揭示模型在何种场景下容易失诚,从而帮助制定更有效的监管和优化策略。 与此同时,推理能力的测试也涵盖多样化的任务类型。
数学推理、逻辑演绎、常识推断等多个维度的评价数据融合在一起,能够让数据可视化展示更加丰富。研究人员常利用雷达图、热力图等形式,描绘模型在不同推理类型上的优势和短板,促进针对性训练和完善。 数据可视化不仅限于静态图表,动态交互式界面同样意义重大。通过交互分析,用户可以根据具体需求调整视角,深度挖掘数据背后的信息。例如,对比两款模型在不同测试环节的细节表现,或在时间轴上观察模型迭代过程中推理与诚实能力的变化趋势。这些功能极大提升了研究效率和结果的可解释性。
在实际应用层面,推理与诚实的平衡极为重要。过分追求推理复杂度可能导致模型生成内容偏离真实,降低整体质量;而只关注诚实性则可能限制模型的创造力和灵活度。通过数据可视化全面呈现两者的权衡,有助于找到最佳平衡点,实现模型性能最大化。 未来,随着人工智能模型规模和复杂度不断提升,基准测试和数据可视化工具也将持续进化。更高维度、多模态的可视化展示,将为理解复杂模型行为提供强大支持。同时,结合用户反馈和实际应用场景的动态数据,将使性能评估更加贴合现实需求。
总而言之,数据可视化作为连接模型性能数据与人类理解的重要桥梁,在映射模型推理能力与诚实表现方面扮演着不可或缺的角色。它不仅提升了评估的效率和深度,也推动了人工智能技术向更智能、更可信的方向迈进。通过持续创新和完善,这一工具必将为人工智能未来的发展注入强大动力。 。