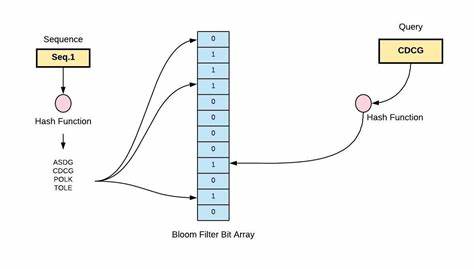
随着数据量的爆炸式增长,如何快速、有效地判断某个元素是否存在于一个庞大的数据集合中,成为计算机科学和工程领域面临的重要挑战。传统的数据结构如哈希表和树结构虽然准确无误,但当数据规模庞大时,检索效率和空间需求往往难以兼顾。布隆过滤器(Bloom Filter)应运而生,作为一种基于概率的空间敏感性极强的集合查询数据结构,极大地优化了查询速度和空间利用率,尤其适用于大数据、分布式系统及数据库索引等场景。布隆过滤器由Burton Bloom于1970年提出,核心目标是以合理可控的误判概率换取更小的存储空间和更快的查询速度。其优势在于能够以极低的时间复杂度判断元素是否非成员,从而避免不必要的磁盘或数据库访问,提升整体系统性能。布隆过滤器的基本结构是一个长度为m的位数组和k个独立的哈希函数。
初始化时,位数组所有位均为0。当插入一个元素时,该元素分别经过k个哈希函数计算出k个索引,将位数组对应位置设为1。查询时同样将待测元素通过k个哈希函数定位k个位,如果任意一个对应位为0,则该元素一定不在集合内,返回查询结果为“否”;若所有位均为1,则元素可能存在集合中,返回“是”,但存在一定的误判概率,即假阳性。布隆过滤器最大的特点是绝不会产生假阴性,确保不存在的元素不会被错误判断为存在,而误判的概率仅和设计参数及插入元素数量相关,可以通过合理调整确保在可接受范围。布隆过滤器的设计参数m和k的选择直接影响其性能。m为位数组的大小,k为哈希函数的数量。
为了满足预期误判概率,必须根据期望插入的元素数n正确设计m和k。数学推导显示,正确配置的k约等于ln2乘以每元素分配的位数m/n,同时误判率与exp(-kn/m)有关。通过科学计算这两个参数,布隆过滤器能够兼顾存储空间与准确性。布隆过滤器的优势体现在极高的时间效率,查询操作只需执行固定次数哈希计算,且不依赖元素数量,查询性能稳定且快速。内存占用小,尤其在需要缓存大量元素状态时,比传统数据结构节省大量空间。应用范围广泛,尤其适合海量数据的集合成员检测,为系统提供初步过滤,减少后续数据处理负担。
例如大规模分布式存储系统HBase、Cassandra中广泛使用布隆过滤器减少磁盘I/O次数,通过先判定元素是否可能存在来避免不必要的磁盘访问。布隆过滤器在网络防火墙、搜索引擎缓存及大数据处理系统中同样发挥重要作用。尽管布隆过滤器有诸多优点,但也存在一些局限性。误判率不可避免,不适合对精确性要求极高的场景。布隆过滤器不支持删除操作,除非采用计数布隆过滤器等变体。同时,存储和计算哈希函数仍需消耗一定资源,设计时需权衡。
针对这些不足,业界提出了多种改进版本,如计数布隆过滤器支持删除,分层布隆过滤器降低误判率,动态布隆过滤器支持弹性扩展规模。实践中,布隆过滤器的实现多样化,以适应不同应用。典型实现采用双哈希技术,大幅减少哈希函数计算成本,通过两次哈希产生多个索引。这样既保证了查询和插入效率,又避免哈希函数计算过度复杂。具体实现中,需要对位数组进行高效存取,通常使用位操作优化空间和速度。通过编程语言和算法库,布隆过滤器可以嵌入各种软件系统。
以Go语言实现为例,利用maphash包生成哈希种子,对输入数据进行双重哈希,计算k个索引,设置相对应位,实现了空间紧凑且查询迅速的布隆过滤器。针对特定应用,还可根据数据统计动态调整参数,提高效率。在大数据时代,布隆过滤器帮我们解决了集合成员检测的巨大难题。它以较小的存储开销实现近乎恒定的查询时间,使得在海量数据环境中实现快速判断成为可能。基于概率判断而非完全精确,使得布隆过滤器非常适合用于预过滤和快速拒绝非成员,提高系统整体响应速度。其广泛应用于数据库引擎、分布式文件系统、搜索引擎及缓存系统,为数据密集型场景提供了优化解决方案。
了解布隆过滤器的设计原则和使用方法,将有助于开发者和系统架构师设计更高效的存储和查询系统。合理配置参数以达到最小误判率,结合具体业务逻辑,布隆过滤器能够显著提升系统的可扩展性和响应速度。总之,布隆过滤器以其巧妙的数学原理和简洁的结构,在现代计算机科学中占据重要地位,成为应对大数据挑战的利器。掌握并灵活运用布隆过滤器,为系统带来更低延迟和更高效的资源利用,助力数字化时代的发展与创新。