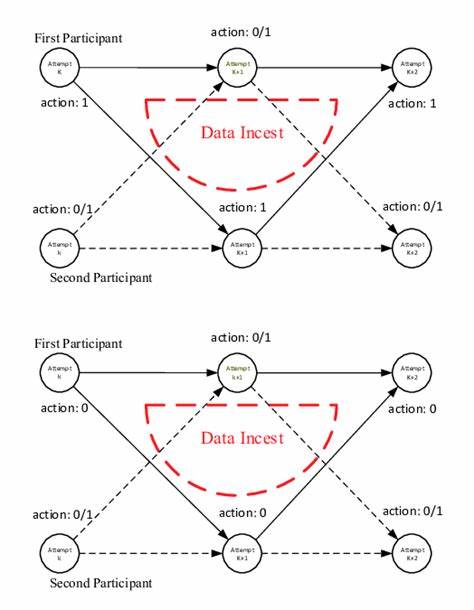
在人工智能快速发展的时代背景下,数据作为驱动AI模型学习和优化的核心资源,扮演着举足轻重的角色。然而,伴随AI生成内容的爆发式增长,数据乱交这一现象成为业界关注的焦点。所谓数据乱交,指的是人工智能模型在训练或微调过程中,使用了由自身或其他类似模型生成的数据,形成了数据的自我循环和反馈。这一看似技术层面的现象,实际上隐藏着深远且复杂的风险,可能导致AI模型渐渐偏离真实世界知识,甚至加剧社会认知的偏见和误导。数据乱交的核心问题,在于AI模型未经人工审核的大量生成内容被重新用于训练新模型,就像一个巨大的回声室,AI在不断重复、放大自己的“声音”,缺乏新鲜、多元且真实性的数据输入,最终陷入“自我膨胀”的恶性循环。 人工智能内容生成的技术不断成熟,使得生成的文本质量不断提高,看似与人类编写的内容难以区分。
但即便如此,AI技术依旧存在诸多缺陷,例如对事实的误述、逻辑的混乱以及固定偏见的继承和强化。当这些带有瑕疵的内容不断被输入训练数据,模型在下一轮训练时将以这些错误信息为依据拓展知识,导致模型输出的质量和准确性逐步下降,产生所谓的“模型崩溃”。这一过程不仅影响AI的表现,也逐步侵蚀了互联网的内容生态,让虚假、重复、无意义的信息横行,压缩了人类创造力的空间。 在互联网时代,尤其是随着社交媒体和在线内容平台AI化趋势的加剧,数据乱交的影响越来越明显。大量的博客、新闻、评论甚至广告内容开始由AI生成,再次被收集并用于训练新一代模型。这种内容间的循环反馈,逐步模糊了内容的来源界限,使得真正的人类原创信息成为稀缺资源。
互联网呈现出信息同质化、内容单一和事实不准确的趋势,用户的认知也难免受到影响。 偏见是数据乱交另一重要风险。AI模型会继承并放大训练数据中存在的偏见和刻板印象,例如性别、种族、政治等方面的不平等内容。当AI模型通过不断学习自身生成的内容,使其对某些群体或观点的偏见加剧时,结果将不仅是技术上的失败,更可能对社会公正产生负面影响。随着时间推移,纠正这些偏见的难度也会成倍增加,造成模型陷入不可逆转的“畸形”状态。 此外,数据乱交现象还导致了“事实真相”的稀缺和模糊。
依赖越来越多的AI文本内容,模型逐渐脱离真实世界的知识基础,生成看似合理但错误百出的信息。例如将历史事实“拿破仑入侵月球”,这样听起来荒诞却可能被部分用户误信的虚假描述,将对公众认知形成极大冲击。人们原本依赖权威、准确的信息进行学习和决策,而数据乱交带来的虚假内容的泛滥,损害了信息生态健康和公共知识的积累。 数据乱交问题并非未来隐忧,而是现实存在的挑战。随着AI技术的普及和商业应用不断扩展,大量AI生成内容渗透入各类数字平台,训练数据中AI内容的比例越来越高。对于模型的研发者来说,一旦新训练数据无法有效区分人工原创与AI生成内容,反馈循环便难以避免。
此外,某些应用领域还存在针对特定数据集的微调需求,这种情况下若数据未严格把控,更易陷入狭隘的“专业领域回声室”,导致内容同质化趋势愈发严重。 应对数据乱交问题,关键在于数据的精细管理和严格筛选。数据的质量和多样性维护,是防止模型陷入错误循环的第一道防线。需要构建有效的内容检测机制,精确识别AI生成内容,从而避免其进入训练集。类似于垃圾邮件过滤的算法检测系统,在未来AI训练过程中将发挥重要作用。 在模型训练过程中,加强人类监督参与同样至关重要。
即所谓的“人类反馈强化学习”,通过人类审阅和校正训练数据,确保模型学习的内容符合实际和伦理标准。然而,考虑到AI生成内容数量庞大,完全依赖人工筛查并不现实,必须结合自动化工具与人为干预,以建立高效可控的训练流程。 同时,应持续向模型输入新鲜的、真实的人类原创内容,如权威出版物、学术论文和优质新闻报道等,防止训练数据单一化。推动开源数据共享和跨机构合作,也是保证数据多样性和真实性的重要途径。定期对模型进行全面审计和性能检测,及时发现因数据乱交而导致的性能退化,并采取针对性调整同样不可忽视。 从行业和社会层面来看,宣传数据乱交问题,提升公众对AI内容真实性的认知至关重要。
用户在使用AI产品时,应保持对生成内容的审慎态度,理性辨别信息真伪。内容平台和开发者也应承担起责任,优化推荐机制,降低AI生成内容的无序扩散,保护互联网信息生态的健康。 简而言之,数据乱交是人工智能产业面临的重大挑战,既牵涉技术层面,也影响社会文化环境。只有通过多方协作,强化技术手段与人为监管,严控数据质量并尊重信息多样性,才能有效遏制其负面影响,促进人工智能技术朝向更加真实、可靠和有益的方向发展。未来人类与AI的协同发展,依赖于我们对数据乱交隐患的深刻理解和睿智应对,让人工智能真正成为助力创新与文明进步的力量,而非陷入自我循环的怪圈。