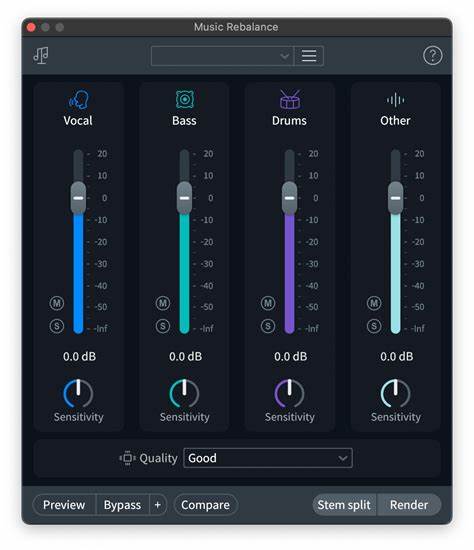
在现代影视作品中,音频体验的重要性愈加突出。然而,许多观众在观看电影和电视剧时常常受到音量剧烈波动的困扰。低声细语瞬间被突然爆炸、枪声或激烈的音乐节奏所淹没,不仅令人不适,还影响了整体的观影体验。Serene-audio-mode作为一款开源音频处理工具,致力于解决这一痛点,通过智能调整视频音轨,实现音量的动态平衡,极大提升了观众的聆听舒适度。 Serene-audio-mode的工作原理基于对音频信号的分析与分段处理。它将一段视频的音轨分割成若干短时间区间,通过计算每个区间的RMS(均方根)响度值,对音频的音量和频率特征进行精准评估。
特别针对爆炸、枪声等低频且声音突兀的部分,通过降低其音量权重达到平衡效果,而对人声和其他重要音频保持尽量不变,确保对话的清晰传递。 与传统的均衡器和音量压缩器不同,Serene-audio-mode不仅仅是简单地削减整体音量或者统一压缩动态范围,而是采用了基于频率权重和动态阈值的智能策略。它根据低频的权重调整(bass_weight),以及子低频切断点(low_cutoff_freq)和中频范围设定(mid_range_freq)等参数,精准找出那些令人不适的“刺耳”声音,然后对其进行相对的压制,避免影响正常的语音和环境音。 这一过程的技术核心融入了Python和Numpy生态系统,借助这些成熟的科学计算库,实现了在开发速度和算法精度之间的良好平衡。虽然当前版本需要用户先用ffmpeg手动提取音轨并执行处理,稍显繁琐,但这种设计也保证了高度灵活性,用户能够根据自身需求调节诸如时间切片长度、淡入淡出时间和增益函数的斜率等参数,使得处理效果更加精准。 具体流程包括先通过ffmpeg从视频文件中提取音频流,然后利用Serene-audio-mode脚本进行音轨的再平衡,最后将处理后的音轨重新叠加回视频文件。
这样,不仅保留了原视频的画面质量,还新增了标记为“serene”的音轨选项,方便后期播放时选择更舒适的版本。 Serene-audio-mode的设计思路顺应了观众对更高品质影音体验的需求。现实中,影视内容中的“轰鸣”与“低语”之间的巨大音量反差,往往让用户不得不停下手中的事情去调整音量控制,十分不便。通过智能音频平衡处理,用户无需频繁调节遥控器,依然能够良好听见对话而不会被突发噪音吓到。这不仅提升了家庭观影的便利性,也避免了夜间观看时打扰家人休息。 另外,Serene-audio-mode的开源特性非常适合技术爱好者和开发者深度定制和二次开发。
随着未来版本计划从Python转向更高效的Go或C语言实现,性能将大幅提升,同时易用性和跨平台支持也会得到强化,这意味着未来有望出现独立的客户端软件或者嵌入式设备集成方案,进一步降低使用门槛。 该工具的出现还带来了对影视后期制作与声音工程的新思考。传统上,音频混音师会通过人工调整将声效与对话做出平衡,一旦影片发布后调整成本极高。而借助自动化智能算法,可以为内容制作团队节省大量人力物力资源,并快速生成多个版本以适应不同播放环境和用户偏好。例如针对家庭影院与移动设备播放环境的不同音频剪裁,Serene-audio-mode提供了极具潜力的技术支持。 在SEO角度上,“视频音轨平衡”、“音频处理工具”、“智能降噪”等关键词在当前影音处理领域有着较高的搜索需求。
Serene-audio-mode作为一个专注于极端音量动态压制,且强调保留对话清晰度的利器,恰好满足了这部分用户的需求。通过分享其技术细节和使用方法,可吸引大量专业用户和影音爱好者关注。 对于视频制作者、影视爱好者、声音工程师以及技术开发者而言,理解并掌握Serene-audio-mode的使用技巧和底层逻辑,有助于推动多媒体音频体验的升级。无论是自制视频的音效优化,还是大型影视项目的后期音轨优化,都可以借助此工具带来的技术红利。 展望未来,随着算法的不断优化和计算性能的提升,类似Serene-audio-mode的智能音频平衡工具将在更多应用场景中得到普及。从直播平台的视频声音实时调节,到智能家居系统的环境声控制,以至AR/VR沉浸式体验的音效微调,都有可能采用此类技术进一步提升人机交互的自然流畅度。
同时,结合人工智能和机器学习技术,未来的语音与噪声识别将更为精准,实现更加个性化的音频处理方案。Serene-audio-mode开创的这一领域,将成为声音处理行业的重要发展方向,为每一位爱好影视的人士营造一个更加舒适安静的聆听环境。 总之,Serene-audio-mode作为一款创新性音频处理工具,成功回应了现代观众对于极端音量波动的痛点需求。它不仅技术先进,且相对易用,极大地丰富了视频内容的呈现方式。对影音爱好者而言,这无疑是提升视听体验的一大福音。未来,随着技术演进和应用拓展,Serene-audio-mode必将成为视频音轨优化领域的标杆,助力我们享受更加和谐宜人的声音世界。
。