在 Kubernetes 中部署微服务时,副本数量看似是一个简单的配置项,但它直接决定了服务在例行维护、滚动升级或突发故障时的韧性。许多工程师直觉认为两副本已经足够,因为只要一个 Pod 宕机,另一个还能提供服务。然而,理论直觉与生产现实往往有差距。将最小副本数设为三,能在极低的成本增量下显著提升抗风险能力,从数学、运维机制与实战角度均能得到解释。 首先从概率模型来量化为何三副本比两副本更安全。把每个 Pod 在某一时刻不可用的概率记为 p,那么单个 Pod 可用的概率就是 1−p。
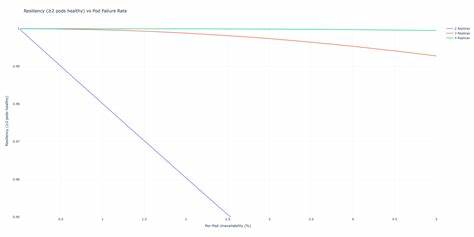
若目标是保证至少有两个 Pod 同时可用,则需要计算二项分布下"至少两个可用"的概率。对于两副本,概率等于 (1−p)^2;对于三副本,概率等于 三选二的组合概率加上三者全可用的概率,即 3×(1−p)^2×p + (1−p)^3。把 p 设为 1% 时,两副本满足至少两副本可用的概率约为 98.01%,而三副本则约为 99.9702%。把这些概率换算成每月分钟数,会发现两副本大约每月会有近 860 分钟处于"仅有一副本可用"的脆弱状态,而三副本则只有约 13 分钟。对于线上关键服务,这个差距意味着运维窗口更短、用户影响更少,也降低了在排查问题期间发生二次故障的风险。 概率只是说明为什么三副本在统计意义上更稳健。
Kubernetes 的实际行为进一步放大了两副本的脆弱性。Deployment 的滚动更新受 maxUnavailable 的控制,默认值为 1,意味着在升级过程中会先终止一个 Pod 再创建新的 Pod。如果期望的副本数为 2,那么在滚动更新时系统就会将其中一个 Pod 弹出,短时间内系统只剩下一个 Pod 提供服务。如果此时新 Pod 无法就绪或出现 CrashLoopBackOff,就会导致更长时间的单副本运行窗口,暴露在容量瓶颈甚至完全不可用的风险中。而在三副本情况下,默认的 maxUnavailable=1 仍然允许至少两个 Pod 在升级或维护期间保持可用,从而提供了冗余保护。 为了在实践中实现"持续至少两副本可用"的目标,需要结合多项 Kubernetes 原生机制。
首先,在自动扩缩策略中将 minReplicas 设置为 3,能确保在正常 steady-state 时集群维持至少三个副本。其次,配置 Pod Disruption Budget 可以保障在自愿性中断(例如节点维护、手动驱逐)时至少保留两个可用 Pod。PDB 的 minAvailable=2 是常见且实用的设置,它能在计划性操作时防止控制面将太多 Pod 同时下线。 滚动更新策略也要配合副本数调整。保留合理的 maxSurge 能让集群在更新期间临时创建额外 Pod,确保新 Pod 在旧 Pod 被缩减前就绪;而 maxUnavailable 的设置则决定了在更新过程中可接受的不可用 Pod 数量。对于小规模副本(例如 3 个),将 maxSurge 设为 1、maxUnavailable 设为 1 是一种权衡成本与可用性的常见做法。
对于更大规模的部署,可以使用百分比形式的 maxSurge 和 maxUnavailable,例如 25%,既能控制并发更新的节奏,也能保证足够的就绪容量。 除了这些配置以外,还应关注 Pod 的探针设计。就绪探针和存活探针的时间参数直接影响滚动更新与流量转发行为。过短或不合理的探针会导致健康检查误判,从而触发不必要的重启或延迟就绪,扩大单副本暴露的窗口。将探针的阈值设置为真实流量和启动时间的安全上界,并在预发布环境中验证,可以降低因探针误判导致的生产中断概率。 成本是选择副本数量时不可回避的因素。
三副本意味着在 steady-state 下比两副本多支付 50% 的资源费用,但从风险补偿角度看,这个增量通常是值得的。以面向用户的关键服务为例,数小时的可用性下降或一次中断事故带来的收入损失、品牌信誉下降和工程排障成本,很可能远超持续多付的一段云资源费用。工程决策应结合服务的重要性、SLO/SLA 要求与每次中断的业务成本来衡量副本配置。 并非所有场景都必须使用三副本。开发环境、低流量的后台任务、一次性批处理或非实时的异步 worker,可以在成本优先的前提下选择两副本或单副本,以节省资源。当服务的 RPS 非常低、延迟要求宽松,或者该服务可以容忍较长时间的重启恢复,则可用性目标可以放宽。
不过应当明确分层,将生产关键路径的服务和可容忍中断的服务放到不同的策略组中,避免为了节省整体成本而牺牲关键用户体验。 架构设计中还应考虑拓扑分布以防止单点故障。利用拓扑分布约束将 Pod 播散到不同的可用区或节点池,能把节点级别或机房级别故障的冲击降到最低。结合亲和性和反亲和性策略,确保 Pod 不会全部集中在同一类资源上。对于云原生架构,合理利用多个可用区以及对等集群治理,是提高抗灾能力的重要手段。 监控与告警在保证三副本策略发挥作用中不可或缺。
除了监控 Pod 就绪率和重启次数,还要关注副本数与可用副本数的实时差异、滚动更新持续时间、PDB 触发情况和节点驱逐事件。配套的告警策略应该在可用副本数降到阈值之前通知 SRE 团队,以便迅速采取回滚、加速修复或临时扩容等措施。自动化应对策略如预先定义的回滚策略、快速恢复脚本或自动扩容策略,能在首钟故障发生时缩短影响面。 在持续交付流程中,采用金丝雀发布、蓝绿部署或分阶段发布策略,能进一步降低滚动更新期间的风险。金丝雀发布将流量先引导到少量新版本的副本上,观察关键指标后再逐步扩大范围,这种做法在三副本基础上尤为有效,因为它保证了在实验性副本出现问题时有充足的备用容量。如果业务允许,蓝绿部署可将流量从旧版本一次切换到新版本,从根本上避免在单个 Deployment 中遭遇并行旧新版本竞争导致的复杂性。
最终,选择副本数量是一项权衡工程。三副本之所以成为行业默认,是因为它在高可用性与成本之间提供了极高的边际回报。数学模型、Kubernetes 的更新机制与实战经验都指向同一个结论:相较于两副本,三副本能显著降低单副本暴露的时间窗口,减少运维风险,并在多数生产场景下以较小的额外成本换取极大的可靠性提升。但工程团队仍需基于自身业务风险承受能力、SLO 要求和运行成本做出最终决定,并通过合理配置 Pod 探针、滚动更新策略、Pod Disruption Budget、拓扑分布和自动化恢复流程,将副本策略转化为可衡量的稳定性保证。 。