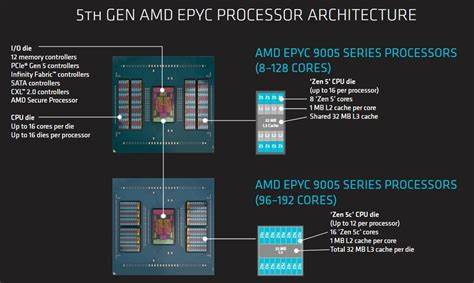
AMD在Zen 5架构上继续推行其独特的"芯片片上模块化"策略,EPYC 9355P便是其中代表作:表面上它是一颗32核的服务器处理器,细看则是通过多项设计权衡来提升每核可用性与带宽表现,而非单纯追求最高核心数。理解这颗芯片的设计理念,有助于在数据中心选型与性能调优时做出更精准的判断。 EPYC 9355P采用多个CPU芯片骰(CCD)加上一颗集中I/O die的组合。每个CCD内部物理上包含八个核心与32MB的L3缓存,但在这款SKU上每个CCD只启用四颗核心,仍保留完整的L3容量,从而显著提升缓存容量与核心数的比值。每个CCD通过AMD所称的GMI-Wide链路连接到I/O die,GMI-Wide使用两条链路并在读写两个方向都提供宽带通道,这在带宽敏感型工作负载中带来明显优势。芯片的提升频率可达4.4 GHz,这对于强调单核/少核性能的场景尤为重要。
I/O die上整合了多达12个内存控制器,形成一条宽宽的768位内存总线,配合DDR5-5200内存时可接近500 GB/s的理论带宽。测试平台通常使用如Dell PowerEdge R6715这类服务器来还原真实部署场景,并可通过BMC访问做更细粒度的NUMA配置测试与性能测量。值得注意的是,I/O die还保留有多达16条GMI链路的能力,用来支撑高核心数SKU,而在EPYC 9355P上则通过GMI-Wide把带宽资源集中分配给八个CCD。 内存访问与NUMA行为是EPYC 9355P的关键性能指标之一。AMD在服务器平台上提供多种NUMA呈现模式以平衡延迟与带宽:NPS1把内存访问跨12个内存控制器条带化呈现,给软件一个"单体"视图但牺牲了一些本地延迟;NPS2把芯片分为两半,每半边配6个内存控制器并组合16核为一个NUMA节点;NPS4把芯片分为四象限,每象限由两颗CCD和3个内存控制器组成;还有按CCD粒度呈现NUMA节点的方式,便于线程亲和调度以共享同一L3缓存。需要说明的是,NUMA呈现与内存地址如何在各控制器间条带化是两个独立设置,调整时需同时考虑。
实测显示,NPS2与NPS4在延迟上仅带来有限的改善,整体延迟仍高于高性能桌面平台,但跨节点访问的惩罚相当温和。在未加载的情况下,跨节点最差延迟通常低于140纳秒,而一些对比平台在极端跨芯片访问时延迟甚至超过180纳秒。换句话说,EPYC的I/O die与Infinity Fabric网络提供了相当紧凑的跨节点互联特性,使得在多数实际负载下NPS1模式的简单性与一致性成为良好默认选择。 在带宽表现方面,GMI-Wide是EPYC 9355P的亮点。单个CCD在GMI-Wide下可达到接近100 GB/s的只读带宽,这明显高于采用单链路GMI-Narrow的桌面CCD(例如某些Ryzen桌面CCD理论值约62.5 GB/s)。更宽的CCD到I/O带宽不仅提升了峰值吞吐,也改善了在高负载下的延迟控制。
桌面平台有时会出现单线程拉满链路而导致其他延迟敏感线程被饿死的角落情形,GMI-Wide通过额外带宽与QoS机制缓解了类似问题。 不过GMI-Wide并非在任何NUMA划分下都万能。测试中用读-改-写模式(read-modify-write)来同时刺激读写路径,可在NPS1模式下获得非常高的整体带宽,某些读写混合负载的测量值可达134 GB/s左右。但在NPS4模式下,单个NUMA节点只有三个内存控制器可用,当一个CCD通过GMI-Wide向其本地节点请求大量读写时,内存控制器资源可能成为瓶颈,使得带宽下降到约96.6 GB/s,延迟也显著上行至数百纳秒量级。因此在需要高带宽的场景中,选择较粗粒度的NUMA配置(例如NPS1)通常更利于带宽利用,而细分的NUMA(NPS4或按CCD)则更适合对缓存局部性与线程亲和有严格控制的工作负载。 缓存与核心分配的策略也值得关注。
每个CCD完整保留32MB L3而只启用四核,意味着每核可利用的L3资源远高于那些在CCD中塞满核心的密度优化SKU。对于延迟敏感或需要大量缓存命中率的应用,这种高缓存/核比是明显优势。另一方面,服务器CCD与桌面CCD在微结构上基本相同,服务器版本的单核落后更多来自于较低的常态频率与更保守的功耗策略,而非架构差异。 在SPEC CPU2017等基准测试中的表现揭示了核心数、频率、延迟与带宽之间的微妙平衡。单线程测试显示EPYC 9355P在单核性能上落后于面向桌面优化的高频CPU,如某些Ryzen型号,但当将桌面芯片的加速关闭并匹配频率时,两者表现接近,说明内存子系统与延迟差异是主要因素。在多线程或带宽敏感的工作负载(例如SPEC的某些浮点基准)中,EPYC 9355P常常表现出色:特定的浮点测试在高带宽需求下会让桌面平台的延迟优势变得无关紧要,而EPYC的宽I/O与多内存通道能提供更高的实际吞吐。
与Intel最新的多芯片设计相比,AMD的策略是明显不同的。Intel更倾向于保持逻辑上的单体性,通过把内存控制器放在多个计算骰上来减小本地延迟,而AMD则自Zen 2起采用一种"枢纽辐射"式的设计:I/O die作为中心枢纽,内存控制器、PCIe与其他全局资源汇聚其上,多颗CCD作为分支接入。早年这种设计被认为会带来本地延迟劣势,但当前的实现把好处放在了更均匀的DRAM访问性能与更灵活的带宽调配上。在实际测量中,AMD的平台展现出一致且可控的跨节点行为,使得在许多实际场景中并不会受限于预期的架构劣势。 对于系统管理员与架构师而言,EPYC 9355P的设计提示了若干可操作建议。首先,除非对内存局部延迟有极致要求,否则默认使用NPS1通常能够获得稳定且易于维护的性能表现。
其次,针对高带宽工作负载(例如科学计算、仿真、某些高性能数据库或内存密集型服务),应尽量避免将需求高度集中在少数NUMA节点上;在有能力进行内存分配与线程亲和优化时,通过策略性地分摊内存分配可获得更好吞吐。最后,像EPYC此类通过增加缓存比与扩大CCD至I/O的通道来提升单核可用性的举措,意味着在选择SKU时不仅要看核心总数,还要评估缓存/核比、链路宽度与目标负载的内存行为。 总的来说,EPYC 9355P并非简单地以32核为卖点,而是通过更高的频率、更优的缓存比与GMI-Wide宽带互连,提升每核的实际可用价值。对于那些无法充分利用极高核心数或受制于内存带宽的复杂负载,这类SKU往往能在单位功耗与单位成本上带来更优的回报。随着Zen家族设计的不断演进,AMD在模块化与集中式I/O之间找到了一个相对稳健的平衡点,使得其在现代数据中心多样化工作负载面前具备很强的竞争力。 。