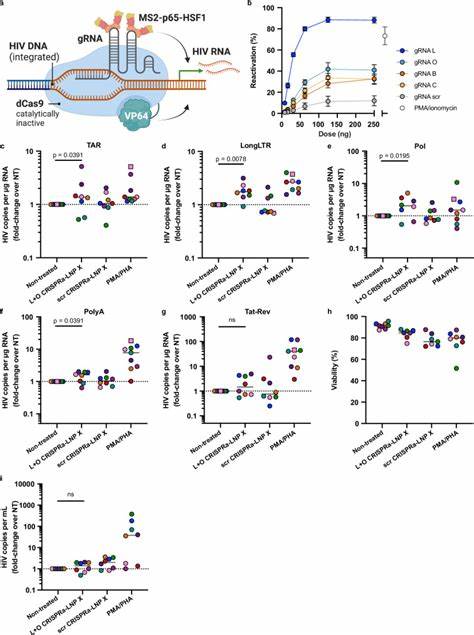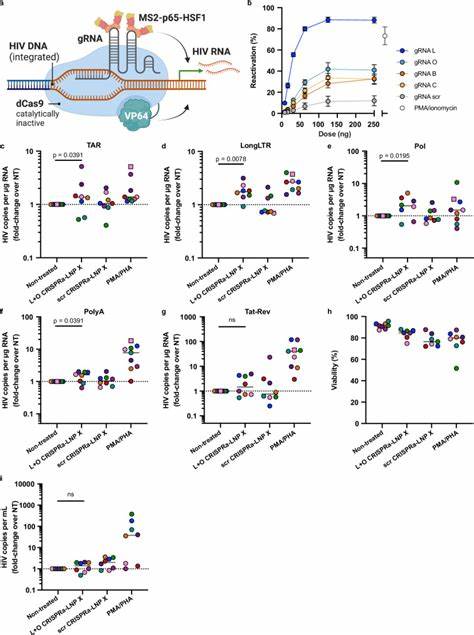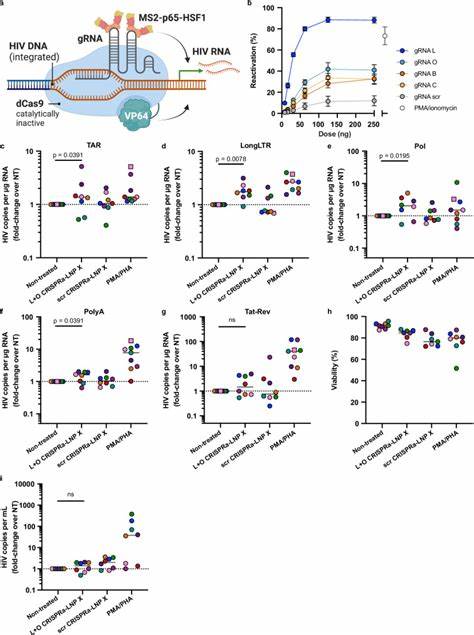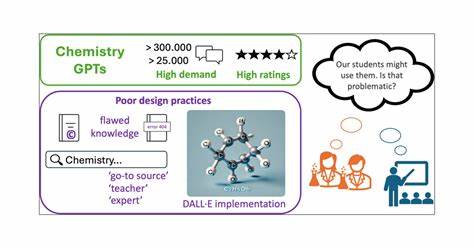
近年来,人工智能技术特别是生成预训练变换模型(GPT)在多个领域展现出了强大的潜力,化学领域也不例外。随着计算能力的提升和海量化学数据的积累,基于GPT的化学模型逐渐被开发出来,用于分子结构预测、反应机制解析以及新药设计等多个方面。然而,尽管公开可用的化学GPT为科研和产业带来了诸多可能,但在实际应用中依然面临着一系列严峻的挑战。首先,公开的化学GPT在数据质量与多样性方面存在显著不足。化学数据本身具有高度专业性和多维度特征,公开数据集往往受限于数据量和质量,难以涵盖复杂的化学反应种类和条件。这种数据缺陷直接导致模型训练效果受限,使得生成的结果在准确性和实用性上存在欠缺。
此外,化学语言复杂且符号丰富,分子结构的表达、反应路径的描述都需要模型具备深厚的领域知识。当前公开的GPT模型多数由通用语言模型改造而来,缺乏专门针对化学专有语言的优化,导致模型在理解和生成专业化学内容时显得力不从心。这不仅影响模型的推断能力,也使得化学反应预测的可靠性难以保证。其次,解释性不足成为阻碍化学GPT广泛应用的重要因素。化学研究通常需要对数据挖掘和模型输出结果拥有清晰的解释理解,但生成模型往往是“黑盒”操作,难以提供具体的机理揭示和推理过程。这种缺乏透明性限制了科研人员对模型结果的信任度,也阻碍了新药发现等领域中模型辅助决策的推广。
另一个较为棘手的问题是模型的泛化能力。化学空间庞大且复杂,各种分子结构之间存在微妙差别,反应条件千变万化。一些公开模型在面对未见过的分子类型或新颖反应时表现不佳,无法有效扩展至实际应用中所需的多样化场景。模型训练过程中缺乏有效的方法来捕获这种广泛的化学复杂性,是导致泛化不足的核心根源。更进一步,伦理和法律问题也逐步显现。公开的化学GPT在数据采集和算法设计过程中可能涉及专利分子结构和商业机密,其开放使用面临法律风险。
同时,不负责任的模型生成可能导致错误信息传播,尤其是在安全敏感的化学合成和药物开发领域,错误预测有潜在严重后果。这对模型的使用者和开发者都提出了高标准的监管和责任要求。性能优化方面,虽有诸多算法改进尝试,但化学GPT模型在计算资源消耗和推理速度上仍需突破,尤其是在处理大规模分子库和复杂反应网络时,计算成本极高,限制了其实时应用的可能性。随着模型复杂度增加,训练时间和硬件需求呈指数增加,这对资源有限的研究机构和初创企业而言是巨大挑战。针对这些问题,研究界与产业界正积极探索多种解决策略。首先,建设更大规模、更高质量的化学数据库是基础,结合专业领域知识提升数据标注的准确性和多样性愈发重要。
其次,针对化学文本和结构的专用编码方式和预训练任务设计,能有效提升模型对化学语言的理解深度和生成能力。解释性方面,融合传统化学知识和机器学习方法,开发可解释AI技术,实现对预测结果的机械逻辑解释,提升用户信任度。模型的泛化能力可通过多任务学习和迁移学习等技术得到强化,使其在更多未知环境下表现稳定。关于伦理和法律风险,建立完善的使用规范与审查机制,确保数据来源合法且使用合规,为产业化应用提供保障。性能优化方面,结合模型压缩、高效推理架构和分布式计算手段,有望缓解计算瓶颈,提高模型在实际场景中的可用性。总之,公开化学GPT作为人工智能与化学深度融合的重要代表,尽管目前面临着数据、模型能力、解释性、法律和性能多方面的挑战,但其在推动化学科学进步方面拥有不可替代的潜力。
未来随着技术的不断进步与跨学科合作的加深,这些难题将逐步得到解决,促进化学研究和相关产业迈入新的智能化阶段。坚实的研究基础、严格的伦理规范和创新的技术应用将共同催生下一代高效、可靠且安全的化学GPT,为人类探索未知化学世界提供强有力的工具支持。