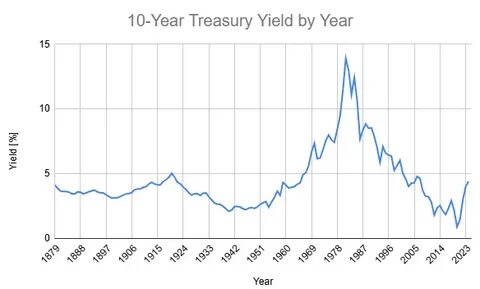
随着人工智能和自然语言处理技术的快速发展,OpenAI发布的GPT系列模型备受关注。自GPT-4上线以来,业界和用户对其性能和应用范围给予高度评价。然而,当GPT-5问世时,许多期待看到巨大突破的用户和专家却发现,两者在很多关键方面表现出惊人的相似性。这一现象引发了社区内广泛讨论,特别是在Ask HN等技术论坛上,用户纷纷探究GPT-5与GPT-4为何几乎没有显著差别。解析这一问题,既需从技术层面理解模型架构与训练方法的基本限制,也需从人工智能发展策略和市场需求的角度进行全方位分析。首先,GPT系列模型的核心技术基于变换器(Transformer)架构,该架构自发布以来就展现出强大的语言理解和生成能力。
每一代GPT在参数数量、训练数据量及微调技术上都有所提升,但随着规模达到一定阈值,模型的性能提升呈现出边际递减的趋势。这意味着尽管GPT-5可能包含更多参数或优化了训练机制,但其整体表现与GPT-4相比并不会产生质的飞跃。在训练数据方面,GPT-5延续了对海量文本语料的学习,这些语料覆盖新闻报道、学术论文、社交媒体以及书籍等多样内容。数据质量和多样性的提升,固然重要,但也受限于现有的语料库和信息承载方式,导致训练出的模型更像是对已有知识的深化理解而非全新认知。因此,GPT-5在生成文本的准确性、连贯性和上下文理解上表现得更加稳健,但整体语义创新能力未必大幅领先。另一方面,模型设计的改进也着重于通用性和安全性。
OpenAI在GPT-5的开发中加强了对有害内容的过滤机制,提升了对敏感话题的处理能力,从而减少模型产生不当输出的概率。这些调整虽使模型更具适用性与合规性,却并不直接转化为用户感知到的智能跃升。此外,迭代过程中的技术创新往往伴随着对计算资源和环境的高要求。GPT-5为了保证稳定性和扩展性,更多采用了优化算法和工程实现上的改良,而非基本架构的革命性变动。这种策略有助于降低开发风险,确保产品的及时发布和商业应用,但也限制了性能的突破。用户体验方面,GPT-5在响应速度、对话管理以及多轮交互的表现上细节更优,这些改进提升了日常使用中的流畅感和实用性。
然而,这些变化多属于"体验型"升级,不易被察觉为核心智能水平的提升,从而让人感觉"几乎没有变化"。市场策略与产品定位也是理解GPT-5与GPT-4相似性的关键因素。作为大型科技公司,OpenAI需平衡技术研发进度与商业产品的稳定性。过于激进的技术跳跃可能带来不可控风险或用户流失,而稳步演进则能够保证用户的持续信赖和生态系统的健康发展。结合投资者期望、行业竞争态势与法律监管,GPT-5的迭代选择更加谨慎,强调实用性和安全性优先。值得注意的是,人工智能领域的研发突破往往不是简单地通过单一代模型实现,而是在连续的积累和多方向的交叉探索中完成。
GPT-5与GPT-4的相似,正反映出行业在追求算法创新、模型规模扩张和应用深度融合之间寻找最佳平衡的过程。未来,随着算力提升、新型训练范式的出现以及多模态人工智能的兴起,语言模型将在理解和生成能力上迎来真正质变。这些变化可能不会在单一版本升级中体现,而是通过长周期和跨领域合作逐步显现。总的来说,GPT-5几乎与GPT-4相同的现象,是技术成熟期的自然表现,既体现了背后复杂的技术挑战,也说明了产品策略的理性选择。对于用户和行业观察者而言,应以更加全面和前瞻的视角看待大规模语言模型的发展,理解其每一步迭代的深层意义,而非仅凭表面差异做出判断。未来的人工智能道路依然充满机遇与未知,期待下一代模型能够在现有基础上实现更加突破性的进展,为人类社会带来更多智慧和便利。
。