随着信息技术的飞速发展,系统产生的日志数据呈现爆炸式增长,如何从庞大的日志数据中快速提取有价值的信息,成为了企业和研究机构亟需解决的重要课题。日志解析作为连接原始日志与下游应用分析的关键环节,其准确性与效率直接影响后续数据挖掘、系统诊断和安全监控等任务。近期,由Prerak Srivastava、Giulio Corallo与Sergey Rybalko提出的《A Word is Worth 4-bit: Efficient Log Parsing with Binary Coded Decimal Recognition》为日志解析领域带来创新视角和技术突破。本文将详尽解析该方法的技术原理、实现优势及其对日志解析行业的深远影响,并探讨未来的发展方向和应用前景。传统日志解析方法多采用基于规则或模板匹配的技术,依赖于人工设计的正则表达式或语义分块,然而,这种方法在面对复杂多变的日志格式时,往往难以捕捉细粒度的结构特征,导致解析结果粒度不够精细,进一步影响日志模板的准确生成。另一方面,近年来深度学习及大语言模型(LLM)在自然语言处理领域的成功推动了基于语义理解的新一代解析器开发。
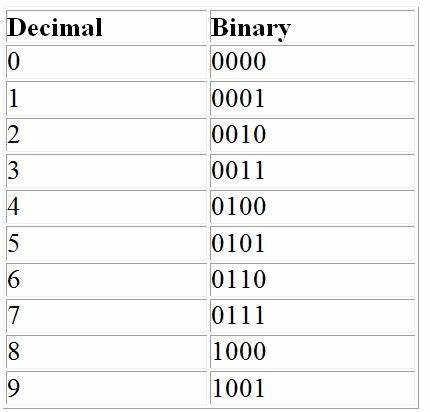
尽管这类方法在准确率上取得提升,但普遍存在计算资源消耗大、推理时间长等劣势,使其在实时或大规模日志处理场景下应用受限。针对以上难题,Srivastava等人提出了一种创新的字符级神经网络架构,能够直接从日志字符序列中学习并生成高精度日志模板。该模型独创性地引入二进制编码十进制(BCD)识别机制,通过将字符级嵌入向量聚合为BCD序列,极大提升了模板表达的细粒度和准确率。BCD码本是一种将每个十进制数字用四位二进制表示的编码方式,广泛应用于数字电路和计算机系统中。将该编码原理引入日志解析中,可以更精准地捕获日志中的数值信息,从而区别不同但结构类似的日志条目。这一点在涉及大量数值参数的工业系统日志或网络设备日志中尤为重要,有效避免了传统解析器将多条不同事件误判为同一模板的情况。
该模型在设计上充分考虑了低资源消耗的需求,体现为字符级的轻量型架构,避免了对大规模预训练模型的依赖。实验证明,该方法在 revised Loghub-2k 数据集及人工标注的工业日志数据集上,表现出与大型语言模型性能相匹配的准确率,同时在计算效率上显著优于现有语义解析器。这意味着,在实际工业部署中能够快速响应实时日志流,降低硬件和能耗成本。技术实现方面,该神经架构通过输入日志的每个字符,学习其隐含语义和模式,并利用BCD识别机制将嵌入转换成高维的离散模板表示,不仅保持对细节的敏感度,同时避免了语义歧义。其训练过程利用监督学习策略,结合人工标注数据和自动生成的先验模板,实现了模型对多样日志格式的泛化能力。此外,研究团队公开了论文与实验结果,推动社区进一步研究和改进日志解析技术。
该方法的应用潜力巨大。在云计算、大数据、物联网等数据密集型场景下,准确及时的日志解析能显著提升故障定位效率,增强安全事件检测能力。尤其是面对复杂设备和多层系统的日志,细粒度的模板识别有助于构建更精准的行为模型和异常检测规则。同时,轻量级的模型设计也满足边缘设备与移动终端的部署需求。未来,结合该BCD识别机制的日志解析技术可进一步结合多模态数据融合、强化学习等前沿方法,提升对日志事件的语义理解和预测能力。此外,跨领域日志解析的迁移学习和自动化标签生成,亦是潜在的研究方向。
随着日志数量和复杂度的持续增加,日志解析技术的智能化和高效化必将成为支撑信息系统稳定运行的基石。四位二进制编码十进制识别方法通过细粒度模板提取和轻量型架构,为解决传统解析挑战提供了新思路。企业和研发人员应密切关注该技术发展,并积极探索其在实际场景中的定制化应用。总的来看,这项创新不仅推动了日志解析技术的技术进步,也为实现高效智能的系统监控和数据分析奠定了坚实基础。面对日益增长的数据压力,只有不断突破解析算法的精细化和效率瓶颈,才能真正释放日志数据的全价值,驱动数字化转型向纵深发展。