在现代数据科学和机器学习领域,高维数据的处理和分析成为了一个普遍而又重要的挑战。面对成千上万的特征变量,如何在保持数据本质信息的同时有效降低数据维度,成为提高模型性能和数据可视化能力的关键所在。主成分分析(Principal Component Analysis,简称PCA)作为最经典、最广泛使用的降维技术之一,正是为了解决这一问题而诞生。本文将带领大家深入探索PCA的工作原理,帮助理解它如何通过数据投影实现信息保留与简化。 首先,我们需要掌握PCA背后的核心思想。简单来说,PCA试图找到在数据集中特征变化最大、信息量最丰富的方向,也就是所谓的主成分。
主成分是一组新的正交轴,这些轴按照最大化数据投影方差的顺序排列。通过将原始数据投影到这些主成分上,可以用较少的维度表达数据的主要特征,从而实现降维。 为了理解PCA如何选择主成分,需要从二维空间减少到一维的例子入手。想象一下,有一组分布在二维平面上的点,我们希望将这些点投影到一条直线上,然后观察这条线上投影点的分布情况。不同的投影方向将导致投影点之间的距离产生变化,有些方向会使投影点高度重叠,信息丢失严重;而有些方向则使投影点尽可能分散,保留了更多关于原始数据的差异性和信息。PCA的目标,就是找到那个使得投影后数据方差(即分散程度)最大的方向,这条方向的单位向量即为第一个主成分。
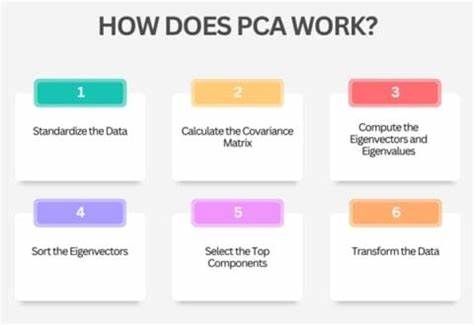
从数学角度来看,设原始数据中的每个点用向量表示为xi,投影方向为单位向量u。投影后的点为xi在u方向上的投影,即xi与u的点积。数据投影在u上的方差可以用向量u表示为u转置乘以协方差矩阵再乘以u的形式。这个协方差矩阵由所有数据点的分布计算而得,反映出各个特征之间的方差和协方差。简言之,协方差矩阵越反映出数据之间的关联,主成分方向则越能捕获这些变化。 为了最大化投影方差,我们需要对函数u^T C u进行优化,其中C是数据的协方差矩阵,u是单位向量。
运用线性代数知识,结合约束条件u的范数为1,我们可以借助拉格朗日乘数法解决优化问题。最终的结论是,主成分u是协方差矩阵C的特征向量,投影方差对应的数值是特征值。特征值越大,意味着沿该特征向量方向的方差越大,信息量越丰富,因此第一个主成分是对应最大特征值的特征向量。 协方差矩阵的构造同样值得关注。假设数据矩阵X是N条样本,每条样本有M个特征,我们先对数据进行中心化处理,减去每个特征的均值,使数据平均值为0。然后通过计算X转置乘以X,除以样本数减一(N-1)得到协方差矩阵C。
C描述了样本中各个特征之间如何共同变化,方差位于矩阵对角线,协方差位于非对角线元素中。对C进行特征值分解,得到所有的特征值和对应的特征向量。 PCA不仅仅是理论上的数学游戏,也在实际应用中发挥着巨大作用。比如在图像识别领域,原始图像像素数据维度极高,通过PCA可以提取主要特征,减少计算资源消耗,提高分类速度和准确率。在基因数据分析中,PCA帮助识别数据中最具代表性的变化模式,简化复杂的基因表达数据,方便科学家发现潜在的生物学意义。在金融领域,通过PCA降维,可以识别出影响市场的主要因素,助力风险管理和资产组合优化。
但PCA也有其局限性。首先,PCA假设数据是线性可分的,主成分反映的是线性组合,对非线性关系挖掘能力有限。其次,它对异常值较为敏感,数据中的极端值可能显著影响协方差矩阵,导致主成分偏差。此外,PCA提取的主成分虽然最大化了方差,但不一定对应最具解释性的特征,特别是在特征含义复杂的实际问题中,需要结合领域知识进行合理解释。 使用PCA时,通常会选择多个主成分进行数据投影,具体数量依赖于对信息保留程度的需求。可以通过累计百分比解释方差来判定选多少主成分,例如选择让累计方差达到90%以上的主成分数,既保证了大部分数据变异信息被保留,也实现了较好的降维效果。
降维后的数据不仅减轻了计算负担,也使数据更易于可视化和理解。 现代机器学习和数据分析工具几乎都内置了PCA模块,从Python的scikit-learn到R语言和MATLAB,操作简便,可以直接对高维数据进行降维处理。同时,有多种算法优化了特征值分解的效率,使得面对百万甚至更大规模数据,PCA依然能快速得出结果。 为了更好理解效果,可以通过可视化手段结合PCA。将高维数据投影到前两个或前三个主成分,绘制散点图,能清晰呈现数据的内在结构和类别间的分布特征,这对探索性数据分析尤为重要。此外,通过交互式工具调整主成分方向,观察方差变化,也帮助加深对PCA机制的理解。
综上所述,主成分分析通过寻找数据中能够最大程度保留方差的正交投影方向,实现了高维数据的有效简化。它不仅减轻了数据处理的计算压力,还有助于揭示隐藏的数据关系。尽管存在一定局限,理解其数学原理和实际应用价值,为数据科学家和研究人员提供了强有力的数据分析利器。随着数据规模不断扩大,PCA的地位愈发重要,将持续推动领域创新和进步。 。