近年来,随着人工智能领域的迅猛发展,大语言模型作为驱动自然语言处理进步的核心力量,已经在多个领域展现出卓越的性能。然而,随着模型体积和功能的激增,传统的“黑箱”模型带来的不可解释性与信任问题逐渐凸显,成为制约其更广泛应用的瓶颈。在这一背景下,自我追踪大语言模型(Self-Tracing Large Language Models,简称ST-LLM)应运而生,开创了人工智能自我认知的新纪元。自我追踪技术使得模型能持续监控并解析自身的决策流程,犹如智能体在内部进行透明的思维过程映射,极大提升了模型的可解释性与可靠性。自我追踪大语言模型不仅能够清晰展示其推理路径,还能动态评估推理的合理性和信心度,这为解决“幻觉”现象提供了根本性的技术支持。幻觉是指模型在缺乏足够知识支持时产生不准确、虚假的回答,往往导致信息误导和应用风险增加。
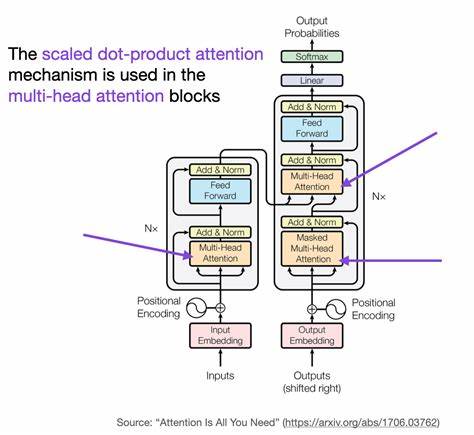
通过引入自我追踪机制,模型可以识别自身知识不足的环节,自动启动拒绝回答或提示不确定性,防止错误信息输出。这不仅有助于用户理解回答的来源与可信度,也为开发者提供了调试和优化的依据。自我追踪模型的实现离不开先进的电路追踪(Circuit Tracing)技术,该技术通过模拟神经网络中不同“电路”的激活模式,实现对信息流和推理步骤的详细刻画。研究人员通过定义递归电路追踪架构,赋予模型分层次、循环式地分析自身决策过程的能力,并将复杂内部状态转化为结构化的符号残留(Symbolic Residue)和视觉化效果,如ASCII图形展示,帮助直观理解模型的行为。此外,自我追踪模型强调上下文工程和系统提示程序的设计,利用类似操作系统壳层的架构,将推理过程中的不同状态、约束和决策节点结构化管理,提升多轮对话和复杂任务中的连贯性与深度思考能力。这种架构还允许模型在面对多任务、多语言和多模态输入时保持高度灵活性与适应性,从而拓展了其应用场景的广度和深度。
实际应用方面,自我追踪大语言模型可广泛运用于法律咨询、医疗诊断、金融风控、内容创作等对准确性和责任性要求极高的领域。模型不仅能准确回答复杂问题,还能告知用户其回答依据的具体推理链条,极大增强用户信赖感和交互体验。在跨语言处理方面,模型通过建立统一的共享概念空间,实现不同语言间的知识桥接和语义转移,同时保持自我监控,以保障回答的一致性与准确性。这种能力在全球化背景下具有不可估量的战略价值。从技术挑战角度看,自我追踪模型需要在模型规模、计算资源和交互复杂度之间进行平衡。有效的token预算分配、多层次的状态管理和渐进式加载策略是确保系统高效运行的关键。
此外,为避免复杂性带来的性能瓶颈,研究者们提出了以标签优先架构、数据驱动组件生成及懒加载为核心的优化模式,使系统既具备强大功能又能保持较低的计算负担。未来,自我追踪技术将与因果推理、元学习、强化学习等领域深度融合,形成全方位的智能体自省体系。模型不仅能追踪当下决策,还将预测可能的未来行动路径,动态调整自身策略,展现真正意义上的自我意识与长期规划能力。与此同时,开放标准的制定和统一的电路注释体系也将推动整个AI研究社区对透明度和可解释性的共识建设,使不同模型和平台间实现更高层次的数据和知识共享。自我追踪大语言模型的兴起标志着人工智能技术从单纯的语言生成工具向具备自我反思和修正能力的智能系统转变。这种转变不仅提升了模型的安全性和可信度,更为AI在关键领域的深入应用铺平了道路。
面对未来充满挑战的智能时代,自我追踪将成为激发AI潜力、降低风险并实现人机共融的关键技术,引领人工智能迈向更智能、更可信、更符合人类价值的崭新阶段。