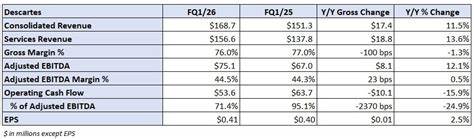
近年来,随着人工智能技术的快速发展,大型语言模型(LLM)成为自然语言处理领域的热点研究对象。苹果公司最新发布的论文《The Illusion of Thinking:Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity》引起了广泛关注,论文围绕大型推理模型(Large Reasoning Models, LRMs)展开,深入剖析了其在实际推理任务中的能力表现及潜在瓶颈。苹果论文对当前主流的推理模型进行了系统性评估,探讨了模型面对不同复杂度问题时的推理效果和内在机制,打破了仅关注最终答案准确率的传统评价范式,开拓了从推理轨迹和思考过程角度理解模型能力的新视野。论文创新性地引入了可控谜题环境,这种环境能够精确调节题目的组合复杂度,同时保证逻辑结构的一致性。通过这种设计,研究者不仅能够量化模型给出的答案,还可以解析模型解决问题的思维路径,揭示其“思考”的深度和策略。实验结果显示,LRMs在面对复杂问题时表现出明显的能力坍塌,具体表现为准确率在某个复杂度阈值之后急剧下降。
这一现象非常关键,因为它提醒研究者即使是当前最先进的推理模型也存在明显的容量和推理极限。此外,苹果团队发现了一种反直觉的“推理规模限制”:模型的推理努力随问题复杂度增加而增长,但在达到一定点后,尽管模型具备足够的推理资源,推理努力却反而减少。这表明模型未能充分利用其推理空间,反映了其内部机制或训练策略可能存在不足,提示未来优化的方向。论文中,作者还对LRMs与传统大型语言模型在相同推理计算量下的表现进行了对比,揭示了三种不同的性能区间。在低复杂度任务中,传统模型竟然在准确率上超过了专门设计的LRMs,显示出某些传统架构的潜力和优势。而在中等复杂度任务,LRMs因其复杂的思考过程开始展现优势,说明“多思考一步”的设计理念在一定范围内有效。
到高复杂度任务时,两类模型均出现了性能崩溃,凸显当前大模型在解决超复杂逻辑推理任务上的局限性。苹果论文还剖析了LRMs在精准计算能力上的短板,指出模型未能成功运用明确的算法规则,而在不同谜题间展现出推理的不一致性,这意味着LRMs仍缺乏真正意义上的算法思考能力。这个发现对于整个自然语言推理领域具有深远影响,因为它挑战了主流观点——即当前大型模型或许只是在“模拟”思考,而非真正理解和执行算法操作。除此之外,研究深入探索了模型推理轨迹中的解题模式和计算行为,通过对解题路径的分析,揭示了模型在推理过程中的策略选择和潜在弱点,帮助研究者更科学地设计训练方法,以增强模型的推理稳定性和可靠性。这项研究的重要意义在于,它不仅为AI推理模型的性能评估提供了更丰富、更细致的指标和方法,同时也为后续提升大型语言模型的推理能力指明了方向。随着越来越多的应用场景需要模型具备强大的推理和逻辑思辨能力,这些深层次的理解将有助于推动技术进步。
总结来看,苹果发布的最新论文极具前瞻性,它警示业界不要陷入对模型“思考能力”的表面追捧,而应深入挖掘模型能力的本质及其结构性限制。未来的大型语言与推理模型,需兼顾精确计算能力和复杂推理过程,才能真正实现跨越式发展。对AI研究者、开发者乃至应用企业而言,理解并解决这些挑战,是迈向真正智能化应用的关键一步。相信随着更多类似研究的涌现,我们对大型推理模型的理解将愈加深入,人工智能的推理能力也将迎来质的飞跃。