人工智能技术的不断进步促使越来越多的用户和开发者寻求更高效、更隐私的AI模型运行方式。Inferencer作为一款专为macOS平台设计的本地AI模型深度控制工具,以其强大的功能和卓越的用户体验,迅速成为行业内的亮点。它不仅支持本地离线处理,确保数据绝对安全,同时还兼容多种先进模型和接口,为用户提供前所未有的控制自由。Inferencer的最大优势在于所有AI处理全部在本地设备完成,无需依赖云端服务,用户无需担忧数据外泄或者网络延迟问题。这在数据隐私日益受到重视的当下,显得尤为重要。Inferencer通过专利申请中的深度学习推理技术,显著提升了推理速度,实现了业内最快的模型运行效率。
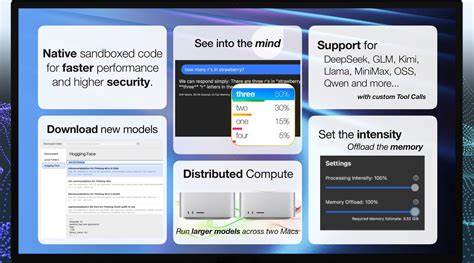
在具体应用层面,Inferencer支持多种主流AI模型,使用户能够灵活选择最符合需求的解决方案,提升应用的智能水平和响应速度。令许多用户惊艳的是,其独有的"Token Inspection(词元检查)"功能。用户可以通过点击词元检查图标,实时查看模型在每一步生成时的概率分布,深入了解模型"思考"的过程。该功能不仅增强了用户对模型推理可信度的感知,也方便开发者进行调试和优化。同时,词元熵显示可以让用户快速识别生成过程中的不确定词元,通过直观的视觉反馈帮助调整和改进生成内容。用户还能通过词元选择和排除功能,主动探索不同词元分支,使生成内容更符合预期,甚至剔除不希望出现的字符,比如外语符号,进一步细化输出质量。
Inferencer的私有服务器功能同样值得关注。它允许用户在本地网络甚至通过互联网建立加密的推理服务,完善保护企业和个人的推理数据安全,确保所有推断过程均在可控制的环境中完成。此功能适用于需要共享模型推理资源,但又担忧数据安全的团队与组织。此外,Inferencer兼容多个主流API,包括Ollama和OpenAI接口,使其不仅易于集成到现有应用开发中,还能作为底层引擎支持丰富的智能应用开发需求。对于想要发挥更大算力的用户,Inferencer提供了分布式推理功能,在多台设备间协调运行更大型模型,打破单机算力瓶颈。这个特性极大地拓展了本地推理的规模和可能性。
Inferencer还支持基于专家网络模型(Mixture of Experts,MoE)的深度调控,可通过控制专家数量来在推理速度和模型智能度之间取得最佳平衡,满足不同场景的效率与精度需求。在实际交互方面,Inferencer允许通过"Prompt Prefilling(提示预填充)"技术来引导模型响应,用户可以预置辅助消息,指示模型执行特定任务、跳过冗长开场白,甚至强制输出JSON或XML格式结果,提升使用的灵活度和精准度。工具自定义功能赋予用户极大的自由度。Inferencer内置网页内容获取等常用工具,且支持用户自行添加工具,让模型在推理过程中调用外部资源或执行特定操作,从而实现复杂的联合智能应用。渲染方面,Inferencer支持高级Markdown和LaTeX渲染,满足技术文档、学术论文等场景的复杂排版需求。未来还将提供代码预览功能,便于开发者实时查看生成代码。
基于自研的模型流式加载技术,Inferencer能够从存储中动态读取大模型内容,极大降低了低配置设备的内存压力,保障流畅使用体验。批处理功能通过合并多个请求为单次推理前向传播,显著提升整体推理吞吐率,特别适合高并发需求场景。产品设有免费基础版与订阅制专业版两种方案。免费版已具备私有离线AI、无限制处理次数、Markdown渲染和模型下载管理等核心功能,适合个人用户及初学者。专业版面向专业开发者和企业用户,提供加密的推理服务器支持、全功能模型流式处理、分布式计算、多代请求批处理、无限制工具和提示定制、专家网络控制等丰富功能,售价为每月9.99美元。通过选择专业版,用户不仅获得更高效且功能强大的AI运行环境,同时支持Inferencer持续的产品开发和创新。
总而言之,Inferencer凭借其深度可控的本地AI运行能力、严格的隐私保护、多样且强大的功能模块,正在为macOS平台带来全新AI应用体验。它不仅满足了对速度、效率和安全的高标准需求,更为开发者创造出一个更加自由且强大的AI模型操控环境。在AI技术与应用快速演进的浪潮中,Inferencer无疑是推动创新和保护用户权益的重要力量,值得广大开发者和企业深入探索和应用。未来,随着更多功能不断加入,Inferencer有望成为本地AI模型运行与定制控制的领先解决方案,引领AI使用进入一个全新的新时代。 。