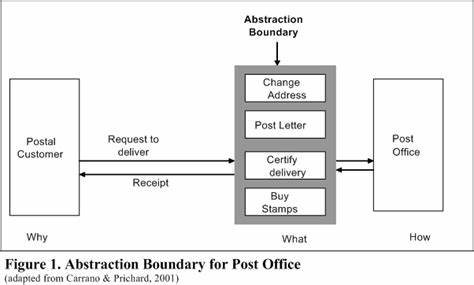
在现代软件开发中,抽象是一项至关重要的技术,它帮助开发者隐藏复杂的实现细节,简化代码逻辑,提高代码复用性和可维护性。然而,抽象并非无代价,过度或不合理的抽象可能会引发性能瓶颈。本文将重点探讨抽象边界与优化边界之间的联系,并通过具体实例解析如何借助调整抽象边界来提升软件系统的性能。 抽象边界是指系统或模块之间划分责任和功能的界限,它定义了组件之间如何交互与传递数据。优化边界则对应着系统中能够发挥优化作用的范围和界限。令人深思的是,抽象边界本身往往就是优化边界。
这意味着,当我们设立或移动抽象边界时,其实就是在重塑系统的性能优化空间。 一个典型的例子便是广为人知的N+1查询问题。该问题通常发生在使用对象关系映射(ORM)技术访问数据库时。当需要获取一个集合内每个元素相关联的数据时,如果代码为每个元素单独发送一条SQL查询,便形成了大量冗余的数据库请求。数据库中所有需要的数据其实早已存在,理论上只需一条合适的查询即可完成数据获取。频繁的单条查询不仅增加数据库负载,还严重影响应用响应速度。
为何会产生N+1查询问题?答案往往是抽象泄露。ORM作为数据库访问的抽象层,无法预判应用程序将会依次请求多少条相关数据,因此它默认每个请求单独处理,导致重复的查询。换言之,抽象层并未能有效整合批量数据访问的需求。此时,优化边界受限于抽象边界,无法内置批量优化策略。 解决此问题的传统手段是将抽象边界“下移”,开发者显式告诉ORM需要批量预加载相关数据。例如,利用预加载(eager loading)机制,让ORM一次性查询所需集合相关数据,将N条查询合并为一条。
这种做法将性能优化交给了高层应用逻辑,扩展了优化边界,但也带来了一定的复杂度和职责分配挑战。 反过来,另一种思路是将抽象边界“上移”,将ORM功能更紧密地集成在编程语言层面。从编译器或语言本身的视角介入数据库查询优化,赋予语言对ORM查询行为的深度理解和转化能力。由于编译器能够对代码进行静态分析和重写规则的应用,它有望自动合并多条查询,消除冗余操作,显著提升执行效率。 Haskell语言在这方面提供了启示。Haskell允许开发者为库定义重写规则(rewrite rules),这些规则能对函数调用进行自动优化。
例如,Haskell中的流融合技术(stream fusion)利用重写规则优化集合操作,将链式调用合并为高效的单遍处理。其核心原因在于Haskell的纯函数特性和声明式语义,使得函数调用的求值顺序和副作用被抽象,方便编译器进行全局优化。 这种“提升抽象边界以扩大优化边界”的思路,体现了语言设计与性能优化之间的紧密联系。将某些中间层功能纳入语言核心,能够让优化过程更加自动化和高效,减少人为干预和错误。对于ORM和数据库查询场景而言,如果语言能够理解数据关系查询的语义,便可在编译阶段识别出N+1查询样式,并用单条批量查询替代,从根本上根除性能隐患。 当然,提升抽象边界并非万能灵药,也存在挑战。
首先,必须保证引入的优化不破坏程序的正确性和预期行为。其次,语言和编译器的复杂度会随之增加,维护和学习成本上升。此外,现实应用中数据库查询往往涉及副作用、事务和并发,语言层面的优化需要充分考虑这些因素,才能安全有效地生效。 抽象边界作为优化边界的概念不仅提醒我们关注软件架构设计时的性能问题,还启发了新一代语言设计和优化技术的发展方向。无论是在数据库访问、集合数据处理,还是更广泛的系统架构中,理解并合理调整抽象边界,都有助于释放软件性能潜力。 未来,随着编程语言和编译器技术的演进,我们或将看到更多抽象功能成为语言内建特性,从而大幅提升软件性能表现和开发效率。
开发者应当认识到抽象和优化并非孤立存在,二者相辅相成。通过对抽象边界的精心设计与动态调整,能够有效拓展优化空间,实现功能与性能的双赢。 综上所述,抽象边界不仅是程序设计中的结构划分,更是软件性能优化的关键节点。应对N+1查询这类典型性能问题,我们既可以下放抽象边界,显式管理批量操作,也可提升抽象边界,让语言层面自动完成优化。理解这一内在联系,对软件工程师、系统架构师乃至语言设计者都极具价值,是提升软件系统效率的重要思维工具。