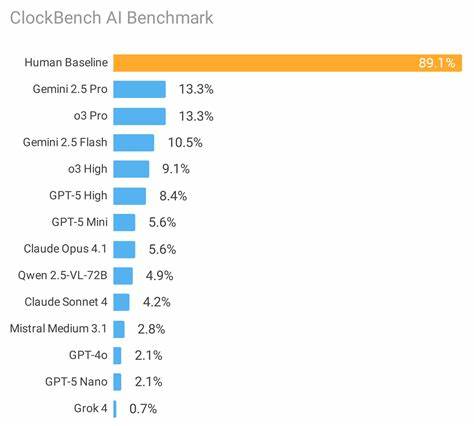
随着人工智能技术的不断发展,视觉推理成为了AI研究领域中的一项关键挑战。视觉推理不仅涉及对图像信息的识别,更需要模型具备理解、推断和解决复杂视觉问题的能力。ClockBench作为一项专门针对视觉推理的AI基准测试,正是在这样的背景下诞生,旨在通过创新的数据集和科学的评测机制,推动视觉推理技术的进步。 ClockBench是由知名研究者Aleksafar团队开发的一套视觉推理AI测试平台,其核心是基于时钟图像的独特数据集和任务设计。不同于传统的图像识别或分类任务,ClockBench通过复杂的时间显示变化和视觉细节,考验模型对图像细节的捕捉能力以及对抽象概念的推理能力。目前公开版本包含10个精挑细选的时钟图像,这些样例是从总共180个时钟图像中选取的,完整版数据集由于保护模型训练的公平性和避免数据泄露而保持私有。
这一设计理念体现了ClockBench对公平性和挑战性的重视。许多视觉推理数据集容易被现有大型模型训练时无意中包含,导致评测结果存在数据泄露的风险。ClockBench选择将绝大部分数据集设为私有,确保对测试模型产生真正有效和公正的衡量。此外,公开数据集的精简版本足以展现模型处理视觉推理复杂问题的基本能力,适合作为初步测试和研究使用。 ClockBench的技术实现也十分注重简洁和高效。用户只需安装Python依赖并运行指定脚本,即可实现对AI模型的评估。
评测流程包含两部分:首先是通过clockbench_evaluate.py脚本调用OpenRouter API运行模型评估,该部分用户需要提供特定的API密钥和指定测试模型;随后通过clockbench_grade.py对模型输出的结果进行打分与分析。这种模块化设计使得评测流程标准化,方便开发者快速搭建实验环境并得出可量化的性能指标。 在AI模型应用的实际场景中,视觉推理能力的提升具有极其重要的意义。无论是自动驾驶系统中对复杂交通标志的理解,还是医疗影像诊断中对细微视觉信息的推断,亦或是智能机器人环境感知和任务规划,强大的视觉推理能力都是实现高效智能决策的基础。ClockBench正是在这一需求推动下,通过模拟高度抽象的视觉任务,检验模型的多层次认知和逻辑推理能力。 从研究角度看,ClockBench提供了一个稳定且具有挑战性的实验平台。
研究者可以利用该平台对比不同视觉推理算法的性能,发现其优缺点并进行针对性的优化。与此同时,基于ClockBench的公开数据集和评测流程,社区可以开展多样化的实验,促进相关领域的学术交流和技术提升。其开源性质也鼓励更多贡献者加入项目,通过Pull Request形式推动代码和数据的持续完善,形成良性发展生态。 另一方面,ClockBench的设计还体现了当前AI伦理与安全意识的增强。通过限制数据集公开范围,它有效避免了训练集与测试集之间的重叠,减少模型过拟合和结果虚高的现象,对维护AI评测的透明度与公平性起到了积极作用。此外,透明的开源许可(MIT许可)使其在商业和学术领域都有广泛应用潜力。
从技术实现细节看,ClockBench依托Python语言编写,整合了诸如requests等主流网络通信库,对接OpenRouter API,为模型调用和数据交互提供了便捷的接口。开发者根据项目说明文档中的安装指引,轻松完成环境配置,快速上手实验。此外,结果以JSON格式输出,结构清晰,方便后续的数据分析、可视化及报告生成工作。在更高层次上,该设计增强了项目的可扩展性和跨平台支持,为未来的功能拓展和模型种类扩充奠定基础。 要认识ClockBench的重要作用,必须结合当前视觉推理AI的发展趋势。近年来,生成式AI、多模态模型的发展极大推动了视觉与语言理解技术的融合,但这也带来了模型泛化能力不足、推理精度有限等挑战。
ClockBench通过具体且具有挑战性的任务,推动模型不仅停留在表面特征识别,而是深入理解时钟复杂的时间指示逻辑及细节变化,从根本上考验和培养模型的逻辑推断能力,提高其对抽象任务的处理水平。 综上所述,ClockBench作为一项专注于视觉推理的AI基准测试平台,以其独特的数据集设计、科学的评测标准和便利的使用流程,成为推动AI视觉理解能力发展的关键工具。它不仅有助于学术界深入探索视觉推理技术,也为企业应用提供了性能验证的标准化途径。未来,随着AI技术日新月异的进步,ClockBench有望持续完善和扩展,助力打造更加智能、灵活且具备深度推理能力的视觉AI系统,从而推动整个AI产业迈向新高度。 。