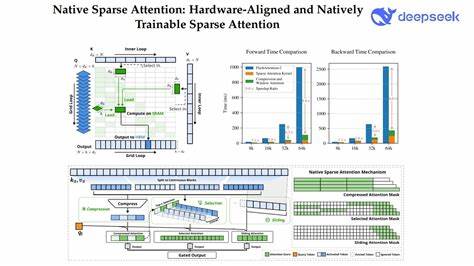
长文本的高效建模一直是自然语言处理领域的核心难题。传统的全注意力(Full Attention)机制虽然在捕捉全局信息方面表现优异,但随着文本长度的增加,计算和存储成本呈现平方级增长,给模型训练和推理带来了极大的负担。面对这一挑战,稀疏注意力机制作为一种有效的替代方案,能够在保持模型性能的同时显著降低计算复杂度,因而受到广泛关注和研究。近期,Jingyang Yuan等学者提出的原生稀疏注意力机制(Native Sparse Attention,简称NSA)在算法创新与硬件优化层面实现了突破,为长上下文建模注入了新的活力。NSA以其动态层次稀疏策略,巧妙融合了粗粒度的Token压缩和细粒度的Token选择,既保证了全局上下文信息的完整捕获,又维护了局部细节的精准表达。相比于以往的稀疏注意力设计,NSA不仅在算法上通过算术强度均衡(arithmetic intensity-balanced)的设计理念提升了计算效率,还针对现代硬件进行了深度优化,使得模型能够高效运行于当前主流计算平台。
特别值得一提的是,NSA实现了从头端到尾端的可训练流程,无需依赖复杂的预训练技术或外部稀疏模式调整,大幅降低了模型预训练的计算资源消耗,同时在多个通用基准测试、长文本任务和指令推理场景中表现出了与全注意力模型持平或更优的性能。研究数据显示,在序列长度达到64k的情况下,NSA在解码、前向传播及反向传播阶段均展示出显著的速度优势,证明其在模型整个生命周期中的高效性和适用性。随着自然语言处理模型向着超大规模和长上下文方向发展,如何在保证模型能力的基础上提升计算效率成为业界抢占技术制高点的关键。NSA所引入的动态层次稀疏策略不仅仅是算法层面的创新,更是一种与硬件协同进化的设计思路,体现了软硬件协同优化的重要趋势。通过结合粗粒度压缩减少入参维度和细粒度选择强化信息筛选,NSA在保障模型语义理解能力的同时,有效压缩了计算资源,使得长文本应用场景如长篇对话、文档理解和复杂推理变得更加实用和高效。此外,NSA的可训练特性使其能够与现代深度学习训练流程无缝集成,这不仅简化了模型开发与调试环节,还促进了技术在实际工业界的快速落地。
与传统的稀疏注意力模型相比,NSA无需复杂的稀疏模式设计或手工调参,用户即可基于统一框架灵活适配多种任务和硬件平台,大幅提升了应用的广泛性和易用性。随着该技术的推广和完善,未来自然语言处理模型有望突破现有长度限制,以更长的上下文捕捉能力驱动更深层次的语言理解和生成。同时,NSA在提高计算效率方面的优势也为能源消耗降低和绿色人工智能的发展赋能。原生稀疏注意力机制开辟的新路径不仅为学术界提供了丰富的研究素材,也为产业界带来了新的增长契机。人工智能应用正不断渗透到教育、医疗、金融、法律等多个行业,长文本建模技术的提升将显著增强系统的知识处理能力和交互体验。未来,结合更多硬件创新与算法优化,稀疏注意力将成为自然语言处理领域不可或缺的重要组成部分。
总的来说,原生稀疏注意力机制以其硬件适配性及端到端可训练特性,标志着长文本建模进入一个全新的时代。这种设计思路不仅合理兼顾了效率与性能,还为模型在更大规模、更复杂任务上的应用铺平了道路。随着相关技术的不断成熟与应用扩展,期待NSA及其衍生技术在推动自然语言处理领域实现更大突破中发挥关键作用。