在当今编程语言层出不穷的时代,性能成为语言推广的重要卖点之一。Moonbit开发团队最近发布的博客和社交媒体宣传,宣称其语言在快速傅里叶变换(FFT)任务上比Rust表现快出30%,吸引了大量关注和讨论。然而,一位性能工程领域的资深开发者对这一声称提出了质疑,并通过复现和优化Rust代码,证明Moonbit团队基准测试中使用的Rust版本存在明显弱化,完整合理优化后的Rust实现实际上比Moonbit快3.2到3.4倍,完全颠覆了Moonbit的宣传结论。要深入理解这场争议,我们需要从性能基准的重要性开始谈起。基准测试是评判不同方案或语言性能表现的关键依据,但其科学性和公平性决定了测试结果的可信度。特别是跨语言对比时,公平的基线和对等的实现细节至关重要。
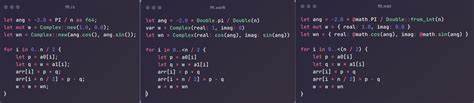
任何人为削弱对比方案的性能,无疑是在误导读者和开发者。Moonbit使用的基准测试围绕经典的Cooley-Tukey快速傅里叶变换算法展开,该算法基于复数运算,结构清晰,且在Rust中的高效实现是广为人知的。问题在于,Moonbit团队提供的Rust实现存在多项明显的低效写法。具体表现为采用非尾递归调用,导致函数调用开销额外增加;递归过程中频繁分配新的向量(Vec)存储数据,带来了高昂的内存分配与缓存负担;缺乏原地(in-place)计算和缓冲重用策略,使得计算过程高度浪费资源。此外,Rust代码缺失针对硬件的编译优化参数,例如-C target-cpu=native,这种优化能够让编译器对关键循环自动向量化,大幅提升运行效率。多方面的设计不合理造就了这个"被压制"的Rust版本,使其性能表现远低于平时Rust开发者的真实能力。
针对这些问题,第三方贡献者迅速提出了多项修复方案。包括将动态分配的Vec替换为性能更优的SmallVec,迭代重构FFT实现消除函数递归,优化循环结构以减少边界检查,开启硬件特定编译优化参数以支持更强大的自动向量化。尤其值得注意的是,一次由5分钟内使用先进人工智能工具如GPT-5辅助编写的Rust版本,就展现出约2.33倍于Moonbit语言执行速度的性能。该修正版的更完善实现不仅是简单代码优化,还是对算法细节和资源管理的精准调整。这些改进措施构成了一幅与Moonbit原始数据完全不同的性能图景,直接挑战了Moonbit团队基于"30%更快"宣称的合法性。不幸的是,尽管这些整改性的合并请求在GitHub等待超过两周且内容被详细记录,Moonbit团队并未回复或合并这些代码,反而继续在社交媒体上大肆宣传未经修复的测试结果。
这种拒绝公开讨论、抗拒修正错误的行为,不仅削弱了他们的信誉,也对整个开源生态造成了负面影响。为何Rust基线被有意或无意地简化至如此低效呢?答案可能在于对技术细节的忽视,也可能是出于营销策略考量。在技术宣传中,因设计不良或恶意操纵而对竞争对手进行不公平对待并非罕见,尤其是在当前竞争激烈的编程语言市场中更值得警惕。对于开发者而言,面对类似的性能报告必须保持警觉精神。单一基准测试往往不足以全面体现语言及其生态系统的性能潜力。实际应用环境中,代码的可维护性、生态丰富度、工具链成熟度、跨平台表现等同样重要。
过分依赖盲目乐观的宣传可能导致误判,浪费宝贵的开发资源。事实上,专业性能比较要求涵盖多维度,多场景的综合测试。不同语言的特性决定了其在不同任务上的表现有高低起伏。以高性能计算为例,Rust的高效内存管理和良好的生态工具,使其在科学计算、系统编程领域愈发受欢迎。而Moonbit等新兴语言尚处于快速发展阶段,性能优势有待严格验证。现实中,任何新语言若想赢得广泛认同,都需基于严谨、客观的比较数据,而非炒作和误导。
业界应当共同促进信息透明,鼓励社区积极参与基准测试的完善,及时修正错误,打造真实、可信的技术宣传环境。此外,Moonbit事件也提醒企业和个人开发者,选择技术时应避免轻信单一来源的性能宣称。充分调研、多方对比,尤其通过开源代码、独立测试来验证性能,才能保障项目稳健发展。与此同时,开源贡献者与技术社区的监督更显得极为重要。通过开源协作纠正测评方法,推动技术创新的同时,提升行业的整体诚信度。总结来看,Moonbit语言所谓"30%快于Rust"的公告,基于不合理的测试对比,根本无法证明其性能领先。
被专业人士优化后的Rust实现以显著优势碾压Moonbit展示,曝光出Moonbit在性能评测上的严重失实。希望相关团队承担起责任,及时修正并公开道歉,为用户和开发者营造一个公平透明的信息传播环境。只有如此,整个编程语言生态才能朝着健康和创新方向持续发展。面对信息纷繁复杂的时代,保持理性和求真决心是开发者最宝贵的品质。 。