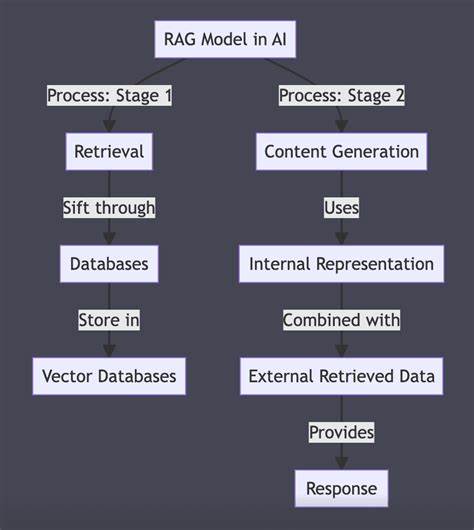
随着人工智能技术的快速发展,自然语言处理领域迎来了诸多创新模型,其中RAG模型因其融合检索与生成的独特机制备受关注。RAG,即Retrieve(检索)、Augment(增强)和 Generate(生成)的缩写,是一种利用外部文档库辅助生成答案的新型模型架构。相比传统纯生成模型,RAG通过检索相关信息并将其集成到生成过程中,提高了回答的准确性和信息的丰富度。 RAG模型的核心思想是在生成回答之前,先从海量文本中检索出与问题最相关的内容,这个步骤称为检索(Retrieve)。随后,模型会将这些检索到的信息“增强”到输入提示(prompt)中,确保生成环节能够基于更加精准和完整的上下文展开推理和文本生成。最后,模型会根据增强后的提示生成最终回答。
因此,RAG模型将传统的检索系统与生成系统进行有机结合,充分发挥两者优势。 检索阶段对回答质量起到了决定性作用。若检索到的上下文内容相关性低、信息不准确,那么即便下游生成模型性能强大,输出结果往往也难以令人满意。换言之,输入的上下文质量是答案优劣的关键因素,这一点在RAG模型中尤为突出。因此,构建丰富、结构化且高质量的文档库是保障RAG系统走向落地应用的重要前提。 增强机制在RAG架构中的作用是将检索回来的文本整合进问题提示,常见做法是在问题文本后附加相关内容。
增强的提示不仅增加了生成模型理解问题的上下文背景,还为其提供了事实依据,从而减少生成的错误和偏差,使得回答更加客观和详实。考虑到生成模型对输入上下文长度的限制,如何选择合适的检索结果片段,确保信息完整且不超出模型处理范围,也是设计RAG系统时必须面对的挑战。 从技术层面来看,RAG模型多采用双编码器架构,分别对查询和文档进行向量化编码,通过向量检索方式快速定位相关信息。此外,生成模型通常基于Transformer架构,如GPT系列或BART,以生成自然流畅且符合语义的回答。整体流程依赖于高效的向量搜索和深度学习生成模型的结合,确保检索与生成环环相扣。 RAG模型的优势不仅体现在准确率的提升,更在于其利用外部知识库动态更新的信息获取能力。
传统的端到端生成模型知识静态,难以应对信息时效性需求,而RAG则能够通过即时检索最新文档实现知识更新,显著增强实际应用价值。这使得RAG在客服问答、专业领域咨询、智能助理等场景中拥有广泛的应用前景。 不过,RAG模型也存在一定限制。检索文档的覆盖范围直接影响到模型的回答能力,若知识库中缺乏相关信息,模型无法生成准确回答;与此同时,检索模块的错误回传会误导生成结果,导致回答偏离真实。这也提示研发人员需要持续优化检索技术和文档库维护,提升系统整体稳定性。 近年来,随着开源社区和企业投入大量资源,RAG技术正在不断迭代完善。
多模态RAG逐渐兴起,结合图像、视频等非文本数据的检索与生成能力,为未来智能交互带来更多可能。与此同时,融合用户反馈机制实现闭环学习,也是提升RAG模型智能水平的关键方向。 此外,在数据隐私和安全方面,RAG系统亦需采取合理措施,确保敏感信息不会被误用或泄露,这对长期推广RAG技术构建信任环境尤为重要。采用加密检索、模型去标识化等方法是当前研究的热点。 RAG模型代表了人工智能问答领域重要的发展趋势,其在提升AI系统回答质量、增强知识时效性和扩展应用边界方面发挥着积极作用。未来,随着模型能力持续增长和检索技术革新,RAG有望成为智能信息服务的核心支撑,为各行业带来深刻变革。
了解RAG模型的机制与优势,有助于更好地把握人工智能发展的脉搏,推动相关技术的应用落地与创新升级。