近年来,随着人工智能技术的迅猛发展,特别是大型语言模型(Large Language Models, LLM)在自然语言处理和智能推理领域的突破,数据库的使用模式正在经历一场深刻的变革。传统数据库系统设计初衷是满足精确、间歇性的查询需求,主要面向人类分析师或基于规则的应用程序。然而,随着智能体(agents)成为数据系统交互的主要媒介,这种传统架构难以适应新兴的、充满探索性和高度冗余的查询浪潮。基于此,业界和学术界开始探索"智能体优先"(Agent-First)的数据系统设计理念,力图打造能够高效承载智能体查询负载的下一代数据库系统。智能体优先的数据系统认为,未来数据查询主要来源于代表用户执行复杂思考和决策过程的智能体,而非单纯的人类输入或静态应用。因此,数据库不仅需要响应准确的SQL查询,更要支持智能体发起的包含"不确定性"、"探索性"的探针(probes),这些探针包括但不限于模式检查、部分聚合查询、推测性连接操作和频繁的回滚操作。
这种查询行为被称为"智能体投机"(agentic speculation),它体现了智能体在面对复杂问题时对数据的反复探索和试错特征。智能体投机带来了传统数据库难以胜任的高吞吐、低效及重复查询负载,也对底层存储、查询优化、事务管理提出了新的挑战。为应对这些挑战,智能体优先的数据系统设计采取了若干创新策略。首先,系统倾向于提供近似查询结果,而非一味追求精确答案。近似查询帮助智能体快速获得足够好的信息,支持其后续决策,而无需等待完整计算,极大提升交互效率。其次,通过多查询优化技术,实现重复子查询的共享计算,避免智能体多次执行同样或高度相似的查询任务。
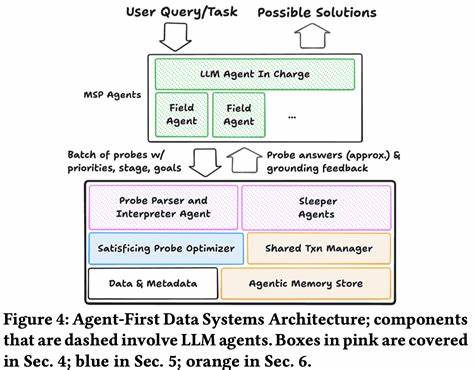
系统还引入智能体记忆存储(agentic memory store),作为语义缓存,保存先前查询的结果、模式元数据以及嵌入式信息,使得智能体后续查询可以基于已有数据来减少重复和盲目探索。此外,数据库系统通过主动反馈机制对智能体进行"引导",例如提供执行成本估计、语义提示和结构性暗示,帮助智能体减少无效查询,提升整体交互效率。具体功能上,智能体通过扩展的探针接口与数据库交流,这种接口将传统SQL查询与自然语言描述相结合,智能体能够说明查询意图、容错容差及所处探查阶段。数据库解析探针后不再追求单条查询的极致性能,而是以整个查询交互环节的总效率为优化目标,使用近似处理、采样查询及增量评估以实现快速响应。同时,智能体优先数据系统支持复杂事务模型,能够管理重叠且分支频繁的 speculative 事务,并通过多世界隔离(multi-world isolation)保证各个探测分支之间逻辑隔离,同时利用物理资源共享实现高效存储。这一体系结构的另一个亮点是对异构数据库的整合能力,允许智能体同时与关系型数据库和文档数据库交互,灵活支撑探索阶段的模糊查询和最终阶段的精确分析。
以MongoDB为代表的文档数据库在此方向有天然优势,其模式灵活、支持嵌入式向量搜索,有助于实现智能体对语义相似数据的检索和早期近似结果的获取。智能体优先数据系统的落地仍面临诸多难题。多租户环境下资源分配、缓存共享、安全隔离等问题亟待解决,保证不同用户的智能体各自独立运行且互不干扰,是体系设计的重要课题。此外,当前大多设计仍停留于单节点假设,而真实应用需求大多涉及分布式架构,如何高效管理分布式智能体记忆、跨节点事务及通信带宽同样是开放挑战。展望未来,智能体优先的数据系统设计与神经符号(neurosymbolic)方法有着天然的契合点。智能体作为神经计算的代表,负责生成假设和模糊推断,数据库作为符号系统,提供结构化逻辑校验与推理规则。
二者深度融合可望催生具有强大推理能力的新型认知数据库,突破单纯数据存储和检索的局限,真正实现智能的数据服务和人机协作。总结而言,智能体优先范式引领数据库系统向更加智能化、交互化和近似计算方向转型。它不仅响应了大型语言模型对数据访问的全新需求,也推动数据库技术从传统精确服务向支持探索式智能推理的宽广场景扩展。掌握和践行智能体优先设计思路,将有助于数据库开发人员、架构师以及数据科学家抢占人工智能时代的数据系统制高点。未来随着智能体技术进步与数据系统创新融合,智能体优先数据系统必将成为支撑复杂智能应用的核心底座,广泛应用于商业分析、科学研究、自动化决策等领域,带来革命性效率提升与用户体验变革。 。