在现代数据工程领域,数据的高效管理和访问成为业务成功的关键因素之一。尤其是在面对多样化数据库和数据仓库的场景中,如何统一数据访问接口,保证数据查询的正确性和性能表现,成为众多数据团队面临的挑战。Boring Semantic Layer应运而生,作为一个轻量级、基于Python且兼容多引擎的数据语义层工具,正逐渐受到业界关注。Boring Semantic Layer由数据工程师Julien Hurault和xorq-labs的Hussain Sultan联合开发,旨在解决大语言模型(LLM)生成SQL查询时常见的误解和错误,以及简化数据访问过程中的复杂性。传统的数据产品多依赖用户界面(UI)进行交互,但他们认为仅依靠多模态编程接口(MCP)可以颠覆这一现状,实现更灵活和高效的数据访问体验。Boring Semantic Layer通过在数据查询层之上建立明确的语义模型,强制执行一致的数据访问规范,从根本上降低了LLM错误率,提高了查询的准确性和稳定性。
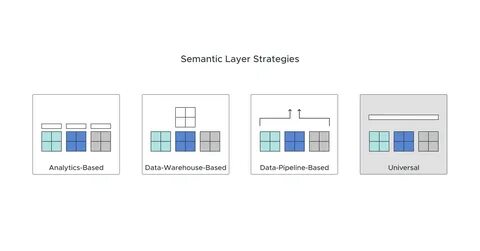
语义层的核心角色是抽象复杂的数据库结构,将表间关系、列含义及上下文封装成易于理解和调用的维度与度量,这不仅帮助开发者在编写查询时减少出错,也使得自动化工具能够更好地解析和生成查询语句。与市场上现有的语义层工具相比,Boring Semantic Layer的最大优势在于其轻量和极简的设计理念。它仅需通过pip命令即可安装,几乎无需额外的服务部署和复杂配置,极大地降低了用户上手门槛。基于Ibis框架,Boring Semantic Layer支持DuckDB、BigQuery、Snowflake等多种数据引擎,使得用户能够在不同的底层存储之间自由切换,同时保证查询逻辑的统一性。使用该工具,开发者首先需要定义语义模型,也就是通过SemanticModel类将具体数据表映射为领域专属的维度和度量。维度指的是数据按何种属性进行切片,比如国家、用户注册时间或某个时间段,而度量则定义了具体的计算指标,例如总收入、独立用户数量或平均订单价值。
这些维度和度量均由Ibis表达式构成,既是Python函数形式的数据库操作,又能够被翻译为针对具体数据库的高效SQL代码,从而实现了后端无关的查询编写。查询方面,语义模型提供了query()方法,允许用户灵活组合多个维度和度量来生成需要的数据视图。比如计算各个出发地航班数,用户只需调用相应模型的query方法即可得到结果数据框。由于限制仅能使用预定义的维度与度量,相较于直接编写SQL,这种方式大大降低了用户出错的风险。此外,过滤条件的引入对于满足具体业务需求至关重要。Boring Semantic Layer支持基于Ibis表达式的过滤,但这类表达式难以序列化,限制了其与大语言模型的协同能力。
针对这一点,开发团队设计了基于JSON格式的简洁过滤方案,用户可以通过标准操作符定义筛选条件,从而更方便地被自动化工具理解和生成。虽然JSON过滤较为基础,难以覆盖复杂的时间或逻辑变换,项目团队引入了一套专门的时序查询机制。用户只需在语义模型中指定时间维度,即可利用time_range和time_grain参数灵活生成日、月、年等粒度的时间维度数据。一句简单的查询即可实现例如获取某月每日航班数,或年初至今的累计数据分析,极大提升了时间序列任务的便捷性。Boring Semantic Layer还支持数据表间的关联,通过Join类抽象不同语义模型之间的连接关系。以航班和航空公司两张表为例,开发者仅需定义对应的Join,用户即可忽略底层的复杂联结细节,自由调用各模型的维度和度量进行查询。
此设计剥离了复杂的数据库结构,让数据消费者能够更加专注于业务逻辑分析。目前,Boring Semantic Layer正在持续迭代,将陆续引入YAML配置界面、图表支持、MCP强化以及缓存与物化功能,目标是构建一个功能齐全而又简洁高效的数据语义层生态。众多数据团队已经在真实项目中测试了这一工具,初步反馈显示其在降低LLM错误率和提升开发效率方面有显著效果。可以预见,随着数据规模和复杂度不断提高,Boring Semantic Layer凭借开放源码、灵活适配多引擎和轻量部署的特点,将成为未来数据平台建设的重要利器。未来,借助语义层,企业不仅能够实现数据访问的标准化,还能赋能智能分析和自动化决策,从而提升业务智能水平。无论是数据工程师、分析师还是AI模型开发者,Boring Semantic Layer都提供了一种高效、易用且可扩展的工具链,助力各类数据驱动项目的快速落地和持续优化。
随着社区活跃度提升,项目欢迎更多贡献者和使用者共同参与开发与完善。随着数据应用对实时性和智能化的需求不断增长,Boring Semantic Layer的出现无疑为数据语义层的发展注入了新的活力,也预示着数据工程领域将迎来更加简洁而强大的工具时代。 。