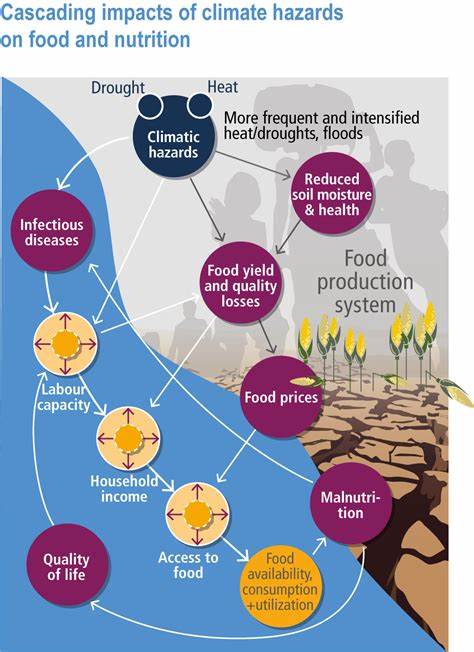
随着大数据时代的到来,企业在数据存储、管理和应用方面面临着前所未有的挑战。大量异构数据散落在分布式存储系统中,传统的关键词搜索方式已经难以满足用户对深层次语义理解和精准匹配的需求。Grepctl作为一种基于语义检索的新兴工具,利用人工智能技术,实现了对数据湖中多种数据格式的智能解析和语义索引,极大提升了数据搜索的效率与准确性。 Grepctl的最大特色在于它集成了谷歌云的多项先进服务,包括Document AI、Vision API、Speech-to-Text和Video Intelligence等,通过智能化的数据预处理和多模态融合,将非结构化和半结构化数据转化为结构化、语义丰富的向量表示。这些128维或768维的向量嵌入使得不同格式和类型的数据之间的语义相似度得以量化,支持在海量数据湖中进行高速精确的相似性搜索。 具体而言,Grepctl支持文本、PDF、Office文档、图片、音频、视频和结构化数据如JSON与CSV等共九种数据模态。
对于文本文件,Grepctl直接采用内容提取与分块技术,保留其原生的结构信息,如Markdown的层次标题,从而确保查询时语义的完整性与上下文关联。PDF文件则通过Document AI的OCR功能,将扫描版和文本版的内容都准确转录,并以章节或段落为单位进行语义分块。对于Office系列文件,工具能够精准提取文档、表格、幻灯片内容,甚至保留幻灯片顺序及备注信息。 图片和视频作为视觉信息表达的重要载体,Grepctl利用Vision API对图片中的标签、文字、物体、面孔等信息进行抽取,视频则通过Video Intelligence API实现场景切分、对象跟踪、文字OCR和语音转录的多管齐下分析,形成完善的多模态搜索标签。音频文件通过Speech-to-Text API的自动标点和语者识别技术实现高质量转录,支持长时段音频的处理,并保证时间戳的同步,方便按时间线进行内容追踪。 大数据查询与检索的核心则依靠Google BigQuery中强大的ML生成的向量嵌入模型和内置的VECTOR_SEARCH函数。
Grepctl自动将处理后的文本内容转换为768维的向量,并存入BigQuery表中,用户可以通过SQL接口直接调用语义搜索功能,实现毫秒级的响应速度。更值得一提的是,Grepctl为用户提供了简单易用的搜索函数及存储过程,包含基础搜索、语义强控搜索、按内容来源筛选搜索和时间范围搜索等,极大地简化了复杂检索的操作难度。 除了传统的命令行界面,Grepctl还配备了Web交互界面、Python客户端和SQL接口,使得不同技术背景的用户均可轻松开展语义搜索。命令行模式便于自动化脚本和运维流程整合,Web界面则贴合非技术人员的使用习惯,Python接口适用于数据科学家和开发者构建定制化应用,SQL接口则完美融合既有的数据仓库应用环境。 用户在配置Grepctl时,只需简单初始化命令指向云存储桶中的数据,即可启动自动化的多模态数据摄取及索引构建。内部的数据处理流水线会为不同格式的数据调用对应的谷歌云API,将原始数据转化成文本内容,随后分块切片并进行向量化处理,最终全部存储进BigQuery数据集。
系统还能自动记录元数据信息,如文件路径、时间戳、数据来源和模态类型,为后续的过滤搜索和溯源分析提供支持。 在实际应用场景中,Grepctl可广泛应用于企业知识库检索、法律文档审阅、医疗影像资料分析、媒体内容管理和客户支持自动化等多个领域。企业通过语义搜索不仅能快速准确地找到相关信息,还能基于相似内容进行智能推荐和洞察挖掘。这一过程大幅度提升了人工检索的效率,避免了传统关键词搜寻时因用词不当或信息冗余带来的困扰。 此外,得益于Google云平台的弹性扩展和高可用特性,Grepctl能够适应海量数据量和高并发访问的需求。无论是全球分布的多数据中心,还是复杂多变的数据结构,都能通过Grepctl实现灵活统一的语义搜索接入。
结合谷歌的Vertex AI文本嵌入模型,Grepctl不断优化向量空间的表示能力,确保语义搜索的前沿性和精准度不断提升。 总结来看,Grepctl作为数据湖语义搜索的利器,不仅实现了多模态数据一站式处理和高效索引,还带来了丰富的访问方式和高度自动化的运维管理。它突破了传统文本搜索的局限,将AI技术深度融入数据检索,帮助企业从海量异构数据中提取核心价值,加速决策制定和业务创新。未来,随着AI模型和云计算技术的持续升级,Grepctl必将在数据智能化应用领域发挥更大潜力,成为企业数字化转型的关键支撑工具。 。