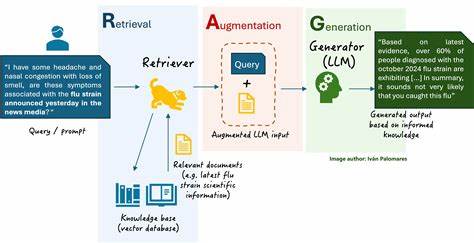
近年来,基于大型语言模型(LLM)的自然语言处理技术发展迅速,尤其是在检索增强生成(RAG)架构的推动下,模型在复杂信息查询、知识检索及内容生成方面表现出色。然而,随着输入上下文信息的持续增多,模型面临着上下文内容遗忘或"上下文衰减"的问题,直接影响其对信息的准确理解和合理生成。为解决这一瓶颈问题,CRoM(Context Rot Mitigation)系统应运而生,旨在有效缓解和管理上下文衰减,从而显著提升基于RAG架构的LLM性能。 CRoM系统的核心优势在于其对上下文信息的动态管理和优化机制。传统的大型语言模型在处理长篇输入时,常因上下文窗口限制导致部分先前信息被遗忘,尤其是在多轮对话或复杂信息检索过程中表现明显。CRoM通过智能分层存储、多模态融合以及实时上下文权重调整等技术,有效保持重要信息的连续性和关联性。
这不仅增强了模型对先前上下文的记忆,也优化了后续生成内容的准确性和连贯性。 RAG架构本质上结合了信息检索与生成模型,利用外部知识库动态检索相关信息,再根据检索结果进行自然语言生成。尽管这一方法扩大了语言模型的知识范围,但文档间信息的时效性和相关性衰减问题依然存在。CRoM系统通过监测上下文中的信息新旧程度与关联性指标,动态调整检索与生成的优先级,避免了信息老化带来的误导,提升输出内容的时效性与信赖度。 技术实现层面,CRoM采用多源数据融合技术,结合文本、元数据及上下文嵌入向量,建立高效的记忆网络。同时引入上下文漂移检测算法,自动识别和纠正上下文信息中的不一致和漂移现象。
通过持续的在线学习与反馈机制,系统不断优化上下文处理策略,确保模型在面对大规模、多变动场景时依然具备稳定表现。 在实际应用中,CRoM系统显示出广泛的潜力。例如,在客服自动化系统中,模型需在多轮交互中保持对用户需求的连续理解,防止信息遗失导致服务质量下降。CRoM通过强化上下文保存与关联,有效提升了客户体验和响应准确率。再如在专业知识检索领域,面对海量文献和数据,CRoM助力模型迅速准确地抓取关键上下文,支持精准智能的内容生成和决策建议。 此外,CRoM的设计考虑了多样化的行业场景需求,能够灵活适配不同数据格式与应用目标。
其模块化架构支持快速集成与扩展,结合行业特定知识库和语义索引技术,实现定制化的上下文管理方案。通过这一策略,企业和开发者能够显著提升基于RAG的智能系统的稳定性和智能水平,且降低了维护成本和复杂度。 面对未来,随着语言模型规模和数据复杂度的不断提升,如何有效缓解上下文衰减将成为推动人工智能服务深入应用的关键。CRoM作为创新的上下文管理技术,不仅解决了当前的技术难题,也为智能对话、知识图谱更新及跨领域信息融合等新兴方向提供了坚实基础。未来研发重点将聚焦于提升自适应能力和多模态信息融合,进一步拓展CRoM在更多复杂环境下的应用边界。 综上所述,CRoM是大型语言模型上下文管理领域的重大突破,通过其科学的上下文衰减缓解机制,为基于RAG架构的LLM带来了显著性能提升。
随着该技术的不断成熟和优化,它必将驱动更智能、更高效的人工智能应用落地,推动整个自然语言处理行业迈向新的高度。 。